DreamVideo-2 —— 复旦和阿里联合多机构推出的零样本视频定制生成框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
DreamVideo-2的主要功能特点
DreamVideo-2是首个无需微调,同时支持主体定制和运动控制的零样本视频定制框架。其主要功能特点包括:
- 无需微调:DreamVideo-2在测试时无需进行复杂的微调,即可实现视频定制。
- 主体定制和运动控制:用户可以通过单张图像定义主体外观,并通过一组边界框序列描述运动轨迹,DreamVideo-2能够生成包含指定主体和运动轨迹的视频。
- 参考注意力机制:利用模型固有的主体学习能力来学习特定主体。
- mask引导的运动模块:通过从边界框中提取的二值mask来精准控制运动。
- 掩码参考注意力:将混合隐空间mask建模方案集成到参考注意力中,以增强目标位置的主体表征。
- 重加权扩散损失:区分边界框内外区域的贡献,确保主体和运动控制的平衡。
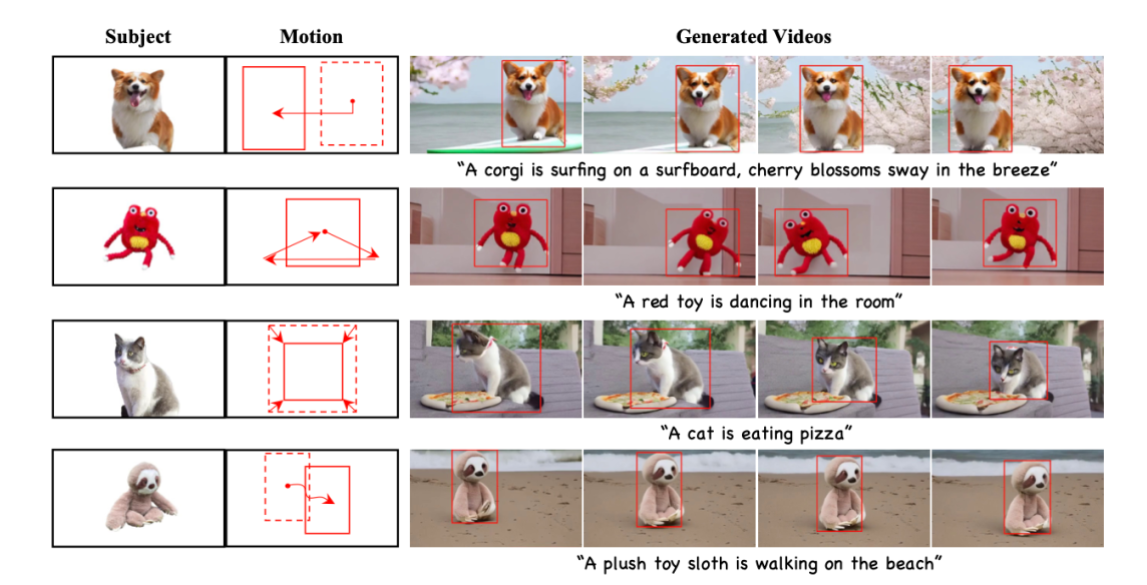
DreamVideo-2的优缺点
-
优点:
- 无需微调:简化了视频定制的流程,提高了效率。
- 主体定制和运动控制:用户可以根据需求灵活定制视频内容。
- 平衡主体学习和运动控制:通过掩码参考注意力和重加权扩散损失有效平衡了主体学习和运动控制。
-
缺点:目前尚未发现明显的缺点,但任何技术在实际应用中都可能面临一些挑战和限制,如数据集的多样性和模型的泛化能力等。
DreamVideo-2的使用方法
DreamVideo-2在推理时无需微调,且不需要修改注意力图。用户只需提供主体图像和边界框序列,即可灵活生成包含指定主体和运动轨迹的定制视频。边界框可以从多种信号中获得,包括首帧和末帧的边界框、首帧边界框及运动轨迹,或参考视频。这些信号随后被转换为二值mask作为输入。
DreamVideo-2的训练方法
训练过程包括从训练视频中随机选择一帧并进行分割,以获得带有空白背景的主体图像,同时从训练视频的所有帧中提取主体的边界框,并将其转换为mask作为运动控制信号。在训练过程中,冻结原始的3D UNet参数,并根据公式联合训练新添加的mask参考注意力、时空编码器和ControlNet。
DreamVideo-2的框架结构
DreamVideo-2的框架结构主要包括参考注意力机制、mask引导的运动模块、掩码参考注意力和重加权扩散损失等组件。这些组件共同协作,实现了无需微调的主体定制和运动控制视频定制功能。
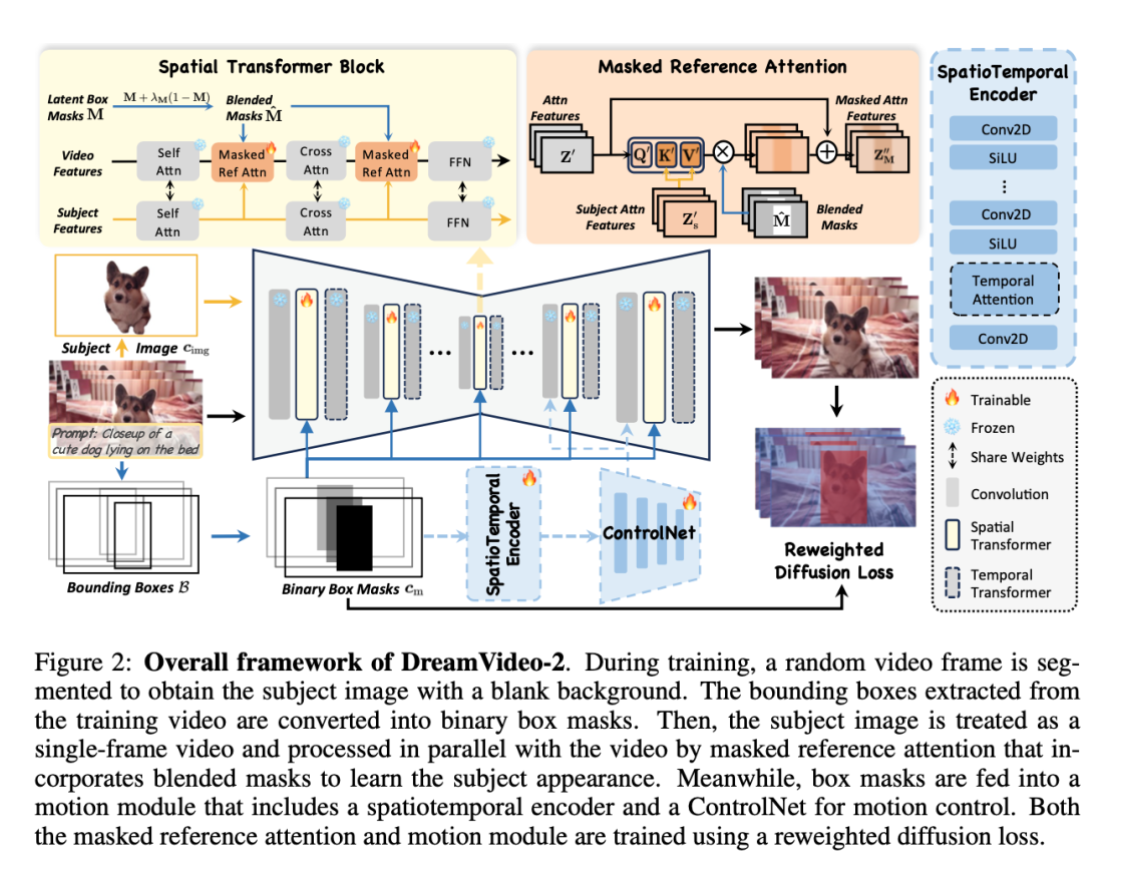

DreamVideo-2的创新点
- 零样本视频定制:DreamVideo-2是首个无需微调的零样本视频定制框架。
- 主体定制和运动控制的平衡:通过掩码参考注意力和重加权扩散损失有效平衡了主体学习和运动控制。
- 大型、全面且多样性丰富的视频数据集:构建了一个大型、全面且多样性丰富的视频数据集,以支持零样本视频定制任务。
DreamVideo-2的评估标准
DreamVideo-2的评估标准主要包括文本对齐、主体保真度和运动控制精度等方面。实验结果表明,DreamVideo-2在主体定制和运动控制方面均优于现有的先进方法。
DreamVideo-2的影响
DreamVideo-2的推出对于视频定制生成领域具有重要意义。它简化了视频定制的流程,提高了效率,同时为用户提供了更加灵活和多样的视频定制选项。此外,DreamVideo-2的构建的大型、全面且多样性丰富的视频数据集也为该领域的研究提供了有力支持。
DreamVideo-2的项目地址
介绍:https://dreamvideo2.github.io/
论文:https://arxiv.org/abs/2410.13830v1
相关文章

Your writing is not only informative but also incredibly inspiring. You have a knack for sparking curiosity and encouraging critical thinking. Thank you for being such a positive influence!