CodeDPO —— 北京大学联合字节共同推出的代码生成优化框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
CodeDPO的主要介绍
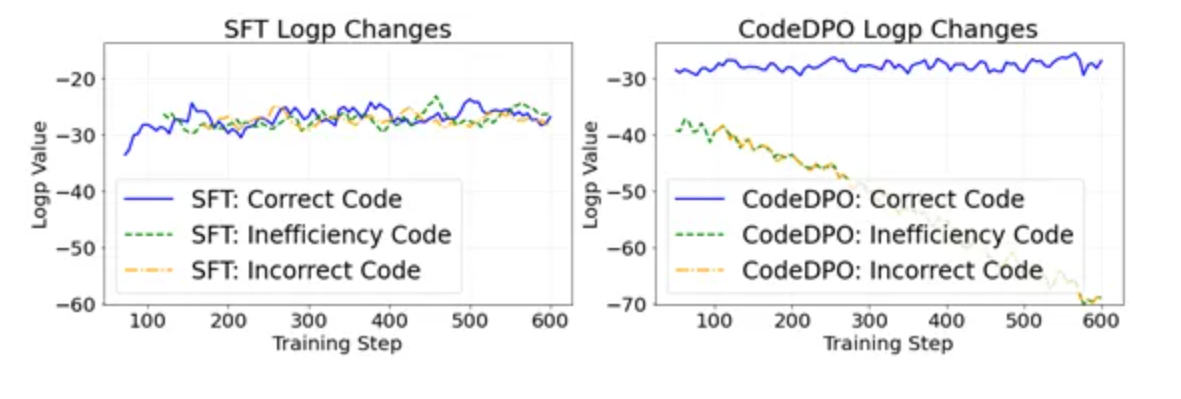
CodeDPO是北京大学李戈教授团队与字节跳动合作推出的创新性代码生成优化框架。CodeDPO旨在通过引入偏好学习机制,提升代码生成模型的性能。该框架克服了现有监督微调(SFT)方法中的局限,将代码生成的准确性和执行效率提升了10%至33%。CodeDPO通过组合正确性和执行效率两个关键因素来定义代码的偏好,利用自验证机制对模型进行训练,以使其更倾向于生成正确和高效的代码。

CodeDPO的功能特点
- 引入偏好学习:通过引入偏好学习机制,CodeDPO能够训练模型在正确与错误解决方案之间做出偏好选择。
- 自验证机制:利用自验证机制对代码和测试用例进行动态评估,确保模型生成解决方案的质量。
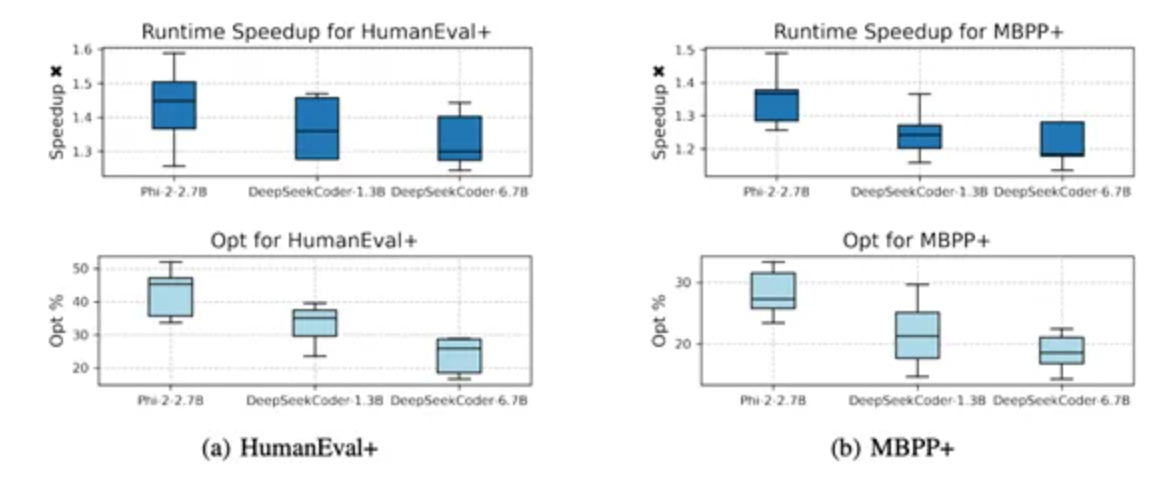
- 提升代码生成准确性与效率:在多个主流数据集上,CodeDPO已显示出高达30%的性能提升,生成的代码在运行速度上平均提升了1.25至1.45倍。
CodeDPO的优缺点
优点:
- 显著提升性能:在多个主流数据集上,CodeDPO显著提升了代码生成的准确性和执行效率。
- 灵活性与可扩展性:CodeDPO能够生成多样化的偏好优化数据,且不依赖于外部资源。
缺点:
- 特定环境下的性能下降:在特定的Python库(如Torch和TensorFlow)中,由于库的样本量不足,CodeDPO可能表现不如预期。
如何使用CodeDPO
目前,关于CodeDPO的具体使用方法尚未公开。但一般而言,使用此类代码生成优化框架通常涉及数据准备、模型训练、代码生成和评估等步骤。用户可能需要根据官方文档或研究团队的指导来进行操作。
CodeDPO的框架结构
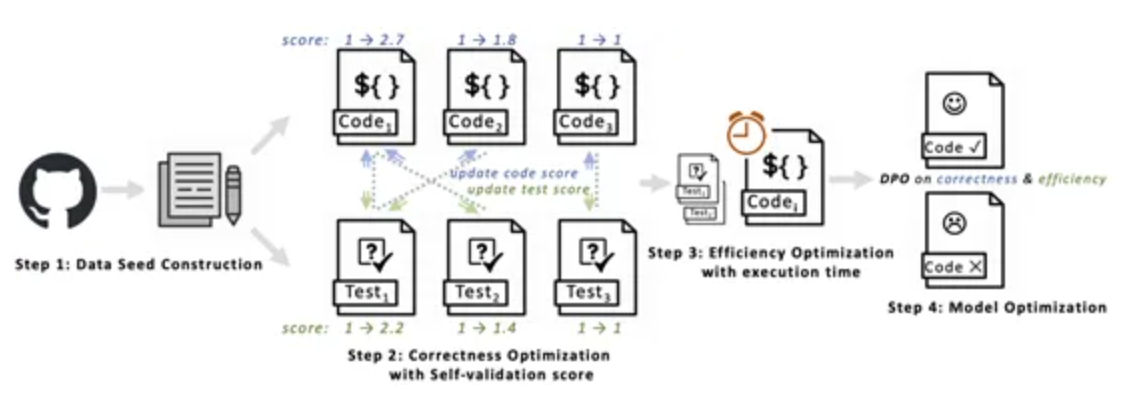
CodeDPO的实施过程包括四个关键步骤:
- 数据种子构建:从开源代码库中收集编程任务的相关数据种子,并进行初步处理。
- 正确性优化与自验证评分:通过自验证机制的引入,模型在生成的同时进行代码和测试的动态评估,为后续的训练提供可靠的数据支持。
- 执行时间效率优化:在选定的可信测试集上测量代码执行时间,以构建效率优化数据集。
- 模型偏好训练:整合上述数据并利用DPO方法来训练多个代码模型。
CodeDPO的创新点
- 偏好学习机制:将偏好学习引入代码生成模型的训练中,以正确性和效率为评估标准,引导模型生成更为高效和准确的代码。
- 自验证机制:利用自验证机制对代码和测试用例进行动态评估,确保模型生成解决方案的质量。这种机制避免了传统方法中静态评估带来的偏差。
CodeDPO的评估标准
CodeDPO的评估标准主要基于代码的正确性和执行效率。在实验中,研究团队通过HumanEval、MBPP及DS-1000等数据集对CodeDPO进行了广泛测试,并量化了其在代码生成准确性和执行效率方面的提升。
CodeDPO的应用领域
CodeDPO主要应用于软件开发领域,旨在通过提升代码生成的准确性和执行效率来助力更加高效与可靠的软件开发。随着技术的不断演进,CodeDPO有望为广大开发者提供便捷的工具,帮助开发团队更好地应对不断变化的市场需求。
CodeDPO的项目地址
论文题目:CodeDPO: Aligning Code Models with Self Generated and Verified Source Code
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
