1月7日·英伟达发布全球最小AI超算Project Digits及RTX 5090显卡
1月7日·周二 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在[图片]这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
英伟达发布全球最小AI超算Project Digits及RTX 5090显卡
在2025年1月7日的CES大会上,英伟达CEO黄仁勋宣布了多项重磅产品。首先,RTX 5090显卡正式发布,国行版定价16499元人民币,其性能是RTX 4090的两倍,支持DLSS 4技术,能够在《赛博朋克2077》中达到238帧每秒的高帧率。此外,全球最小的AI超算Project Digits也震撼亮相,售价3000美金,能够在办公桌上运行200B参数的大模型,提供数据中心级的算力。Project Digits搭载了GB10 Grace Blackwell超级芯片,具备1 PFLOPS的AI性能,预装了NVIDIA DGX基础操作系统和AI软件栈,为开发者提供了一个开箱即用的AI开发环境。这些产品的发布标志着个人AI计算进入了一个全新的时代,为数据科学家、研究者和学生提供了强大的计算支持。来源:微信公众号【新智元】

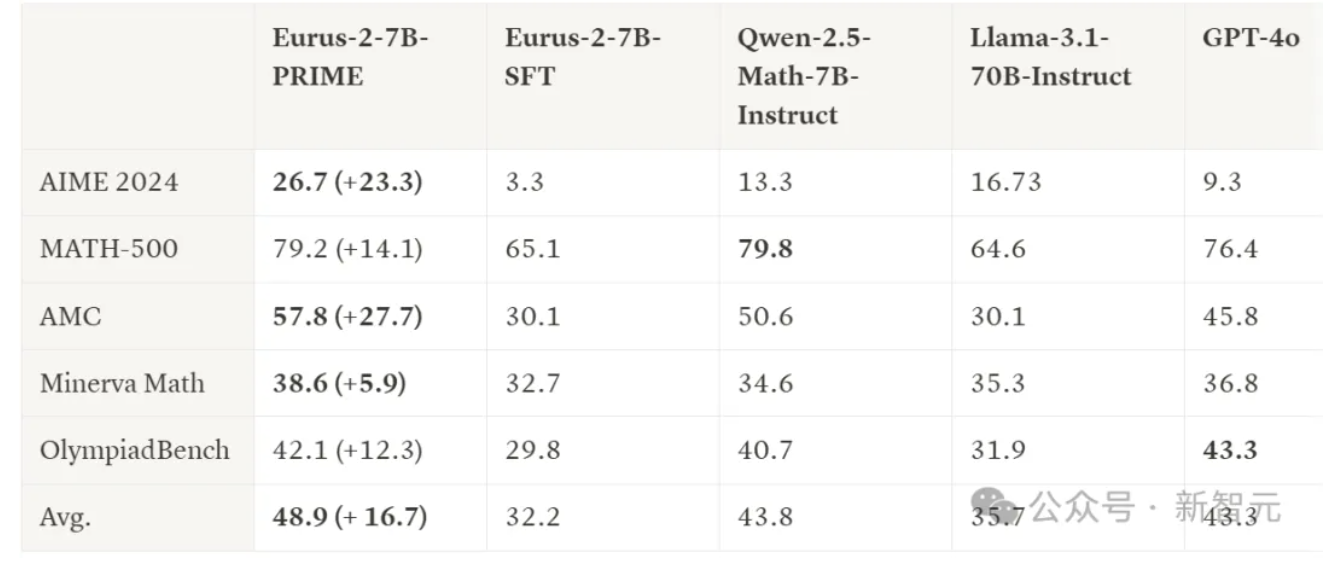
清华等机构推出PRIME模型,以1/10训练数据超越GPT-4o
近日,来自清华大学和UIUC等机构的研究者提出了一种名为PRIME(Process Reinforcement through IMplicit REwards)的新型模型。该模型通过隐式奖励进行过程强化,显著提升了语言模型的推理能力。在多项基准测试中,PRIME的表现超越了传统的监督微调(SFT)和蒸馏方法。具体而言,PRIME在AMC和AIME等测试中平均提高了16.7%,甚至在某些测试中超过了GPT-4o。值得注意的是,PRIME仅使用了Qwen Math 1/10的数据资源,即230K SFT和150K RL数据。研究者们通过设计以动作为中心的链式推理框架和隐式过程奖励模型,实现了对每个推理步骤的评分和优化。PRIME的开源实现为研究人员提供了一个强大的工具,能够在有限的数据资源下,显著提升模型的推理能力。这一成果不仅展示了在数据效率方面的突破,也为未来AI模型的开发提供了新的思路。来源:微信公众号【新智元】
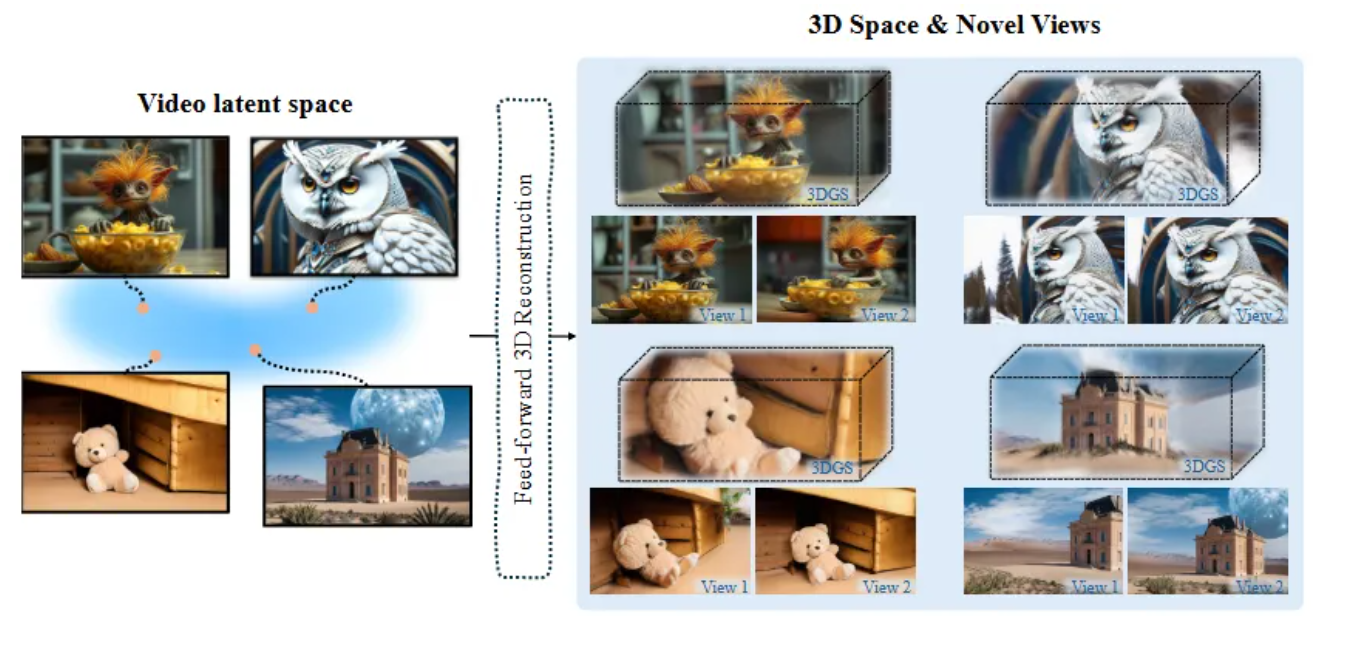
Wonderland模型实现单张图像到高质量3D场景的高效转换
近日,由多伦多大学、Snap Inc.和UCLA的研究团队开发的新型模型Wonderland在单视图3D场景生成领域取得了突破性进展。该模型能够从单张图像生成高质量、广范围的3D场景,显著提升了3D场景生成的效率和质量。Wonderland通过结合视频生成模型和大规模3D重建模型,实现了从单张图像到多视角视频的扩展,并进一步生成3D场景。其创新的双分支相机控制机制和大规模latent-based 3D重建模型(LaLRM)使得生成的3D场景在几何一致性和视觉质量上均优于现有方法。实验结果显示,Wonderland在多个数据集上的表现卓越,生成速度极快,仅需约5分钟即可完成一个完整的3D场景生成。这一技术为建筑设计、虚拟现实、影视特效和游戏开发等领域提供了新的创作工具,展现出广阔的应用前景.未来,Wonderland团队将继续优化其对动态场景的适配能力和对真实场景细节的还原度,推动3D场景生成技术的进一步发展。来源:微信公众号【机器之心】
雷鸟V3 AI眼镜发布,搭载阿里定制大模型及高清摄像头
雷鸟创新近日发布了全新款AI拍摄眼镜——雷鸟V3,定价1799元,将于本月10日起现货发售。该眼镜搭载了高通骁龙AR1平台,具备32G内存,重量仅为39克,比Meta轻13.3%。在AI功能上,雷鸟与阿里通义合作,内置了定制化的多模态大模型,支持多模态问答,能够识别眼前看到的一切并提供准确回答,准确率高达98%。此外,雷鸟V3还配备了1200万像素的高清摄像头,支持4K照片和1080P/30fps视频拍摄,画质堪比手机。雷鸟V3不仅在AI功能上表现出色,其拍照能力也极为强大,采用索尼IMX681传感器和多项图像优化技术,确保了高质量的拍摄效果。此外,雷鸟V3还承诺提供三年的免费AI更新维护,进一步提升了用户体验.该眼镜的发布为智能眼镜市场带来了新的选择,适合多种应用场景。来源:微信公众号【量子位】

陈丹琦团队推出MeCo方法,减少数据量同时提升大模型性能
普林斯顿大学陈丹琦团队近日提出了一种名为MeCo(Metadata Conditioning then Cooldown)的新方法,能够在减少三分之一训练数据的情况下,保持大模型的性能不减。该方法通过引入元数据来加速大模型的预训练过程,而不需要增加额外的计算开销。MeCo方法包括两个阶段:预训练阶段和冷却阶段。在预训练阶段,将元数据与文档拼接进行训练,而在冷却阶段则使用标准数据继续训练。实验结果表明,MeCo在不同模型规模(600M到8B)和数据源下均能显著提升性能,其平均性能与使用240B标记的基线相当,但使用的数据减少了33%。此外,MeCo还展示了其在引导语言模型方面的潜力,例如通过使用特定的元数据来提高常识性任务的性能或降低毒性生成的可能性。这一创新为大模型的训练提供了新的思路,有助于在资源有限的情况下实现更高效的模型开发。来源:微信公众号【量子位】

【今日案例】
特朗普为何要买下格陵兰岛
https://yuanbao.tencent.com/bot/app/share/chat/e2e1002b23a7db961e4625ebeb7a3cdf
相关文章
