DeepSeek登顶中美AppStore!全过程要点分析→
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
DeepSeek主要介绍
DeepSeek是杭州深度求索人工智能基础技术研究有限公司(简称“深度求索”)旗下的开源大模型平台。该平台由幻方量化公司支持,专注于研究世界领先的通用人工智能底层模型与技术,挑战人工智能前沿性难题。DeepSeek已经发布并开源了多个百亿级参数大模型,如DeepSeek-LLM通用大语言模型、DeepSeek-Coder代码大模型等,旨在通过自然语言处理和机器学习算法来理解和回应用户的查询,提供高效、智能的服务。

DeepSeek功能特点
- 开源与商用授权:DeepSeek全系列模型已经完全开源,并且免费商用,为广大开发者和企业提供了经济实惠的选择。
- 多模态能力:DeepSeek-VL能够在不丢失语言能力的情况下融入多模态能力,处理包括逻辑图、网页、公式识别、科学文献、自然图像等多种类型的数据。
- 高分辨率图片输入:能够接受高达1024×1024的大尺寸分辨率图片作为输入,识别图片中的细小物体。
- 强大的编码能力:DeepSeek Coder模型通过深度学习和自然语言处理技术,能够更准确地理解用户的编码需求,并提供高质量的代码生成服务。
- 高效的推理速度:通过优化架构和算法,DeepSeek在处理长文本和复杂任务时表现出色。
DeepSeek框架结构
DeepSeek采用了先进的模型架构,如DeepSeek-V3就采用了Mixture-of-Experts(MoE)架构,总参数量为6710亿,每个token激活370亿参数。此外,还使用了多头潜在注意力(MLA)机制、无辅助损失的负载均衡策略、多token预测(MTP)训练目标等创新技术,以提高模型的计算效率和性能。
DeepSeek创新点
- MoE架构:通过动态选择最合适的专家进行计算,提高了计算效率。
- MLA机制:通过低秩联合压缩键值缓存需求,减少了推理期间的计算量和存储空间。
- 无辅助损失的负载均衡策略:避免了传统负载均衡方法对模型性能的负面影响。
- FP8混合精度训练:首次验证了FP8训练在极大规模模型上的可行性和有效性,降低了训练和推理成本。
- 长上下文扩展技术:支持128K上下文窗口,显著增强了处理长文本的能力。
DeepSeek评估标准
DeepSeek的性能评估主要基于多个公开评测榜单和真实样本外的泛化效果。例如,在MMLU基准测试中准确率达85.6%,在GSM8K数学任务中准确率达92.3%,在HumanEval代码生成任务中通过率提升15%。此外,还通过处理速度、延迟、上下文窗口等指标来评估模型在实际应用中的表现。
2025年1月,DeepSeek发生了以下几件重要事件:
发布DeepSeek-R1模型:1月20日,DeepSeek正式发布了推理大模型DeepSeek-R1,并同步开源模型权重。该模型性能与OpenAI的o1正式版持平,且成本价格低廉,在许多第三方测试中表现优于OpenAI的最新模型o1。
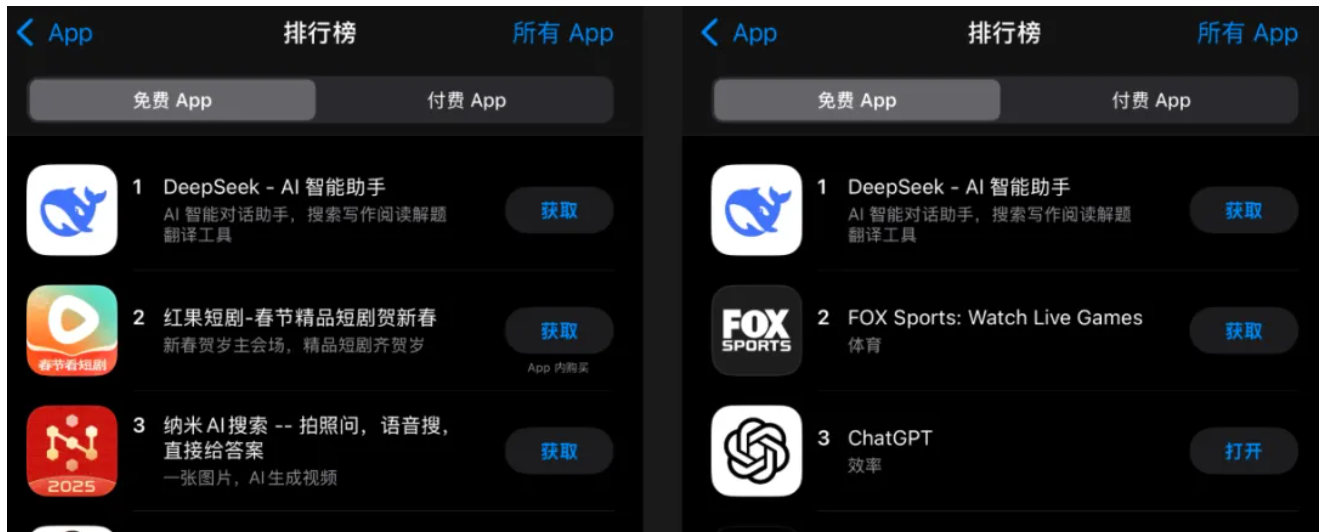
登顶应用商店排行榜:1月27日,DeepSeek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。
服务器宕机事件:1月26日,DeepSeek曾出现短时闪崩现象,1月27日DeepSeek官网显示网页/API不可用。DeepSeek回应称,这可能是由于新模型发布后用户访问量激增,服务器一时无法满足大量用户的并发需求。
获得高度评价:微软首席执行官萨蒂亚·纳德拉和谷歌前CEO埃里克·施密特等大佬对DeepSeek评价颇高。纳德拉表示DeepSeek的新模型令人印象深刻,施密特则认为中国在过去6个月以非同寻常的方式迎头赶上。
引发行业震动:DeepSeek-R1的发布震动了美国科技界,引发了Meta内部的恐慌,工程师们开始连夜尝试复制DeepSeek的成果。国外媒体纷纷聚焦DeepSeek,认为中国大模型的新进展为硅谷敲响了警钟。
DeepSeek行业震动前因分析
技术突破与创新:
- DeepSeek在2025年1月20日正式发布了推理大模型DeepSeek-R1,并同步开源模型权重。该模型在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。这种技术突破使得DeepSeek-R1在数学、代码、自然语言推理等任务上的表现能够比肩OpenAI的o1模型。
- DeepSeek-R1的预训练费用仅为557.6万美元,训练成本不到OpenAI GPT-4o模型的十分之一。这种高性价比的人工智能模型使得DeepSeek在市场竞争中具备了显著的优势。
市场与行业背景:
- DeepSeek-V2的发布引发了连锁反应,字节跳动、百度、阿里、腾讯、智谱AI纷纷跟进,大幅下调其大模型产品的价格。这场价格战的影响力甚至跨越太平洋,引起了硅谷的高度关注。
- DeepSeek被冠以“AI届的拼多多”之称,其创始人梁文锋表示,降价一方面是因为探索下一代模型的结构中成本先降下来了,另一方面也觉得无论是API还是AI,都应该是普惠的、人人可以用得起的东西。
人事变动与战略布局:
- 几周前,DeepSeek出现了一个引人注目的人事变动,雷军以千万年薪成功挖角了罗福莉,并委以小米AI实验室大模型团队负责人重任。罗福莉于2022年加入幻方量化旗下的DeepSeek,在DeepSeek-V2和最新的R1等重要技术报告中都能看到她的身影。
- 一度专注于B端的DeepSeek也开始布局C端,推出移动应用。截至发稿前,DeepSeek的移动应用在苹果App Store免费版应用最高排到第二,展现出强劲的竞争力。
DeepSeek行业震动后果分析
服务器宕机事件:
- 2025年1月26日,DeepSeek曾出现短时闪崩现象。1月27日,DeepSeek服务状态页面显示,DeepSeek网页/API不可用。DeepSeek回应称,此次事件可能是由于新模型发布后,用户访问量激增,服务器一时无法满足大量用户的并发需求。
登顶应用商店排行榜:
- 1月27日早间,DeepSeek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。这一成就标志着国产人工智能技术的卓越进步,也对国际科技市场产生了深远影响。
行业震动与国际关注:
- DeepSeek-R1的发布震动了美国科技界,引发了Meta、OpenAI及谷歌等公司的内部快速技术分析,争分夺秒,试图应对来自DeepSeek的压力。甚至在职场论坛上,有Meta员工透露,公司的“A部门”因R1而陷入“恐慌模式”。
- 美国《华尔街日报》报道称,DeepSeek-R1的出色表现已经给美国科技行业留下深刻印象,从业者纷纷称赞深度求索的工作取得了重大突破。OpenAI公司前高管扎克·卡斯(Zack Kass)直言,美国试图通过制裁限制中国的AI发展,但资源的限制反而激发了中国科研人员的创造力。
市场与投资影响:
- DeepSeek-R1的发布宛如一颗沉重的石子打入AI行业与AI投资的湖水之中,甚至开始令越来越多人警觉AI投资可能存在的泡沫。美股大V“THE SHORT BEAR”在社交媒体上表示,DeepSeek创造了一个AI巨头们的痛苦时刻,而投资者必须对此敲响警钟。
- 海外知名财经博客Zerohedge24日撰文,称DeepSeek的出现和其廉价的训练成本,正在对美国此前宣布的5000亿美元AI基建计划形成巨大的打击。网络社群里,越来越多的人把DeepSeek的出现与近期英伟达的回调联系在一起。1月24日,英伟达股价大跌3.12%,报142.62美元/股,创下公司在年初CES展产品不及预期表现后的最大跌幅。
相关文章
