Valley —— 字节跳动推出的多模态大模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Valley是什么
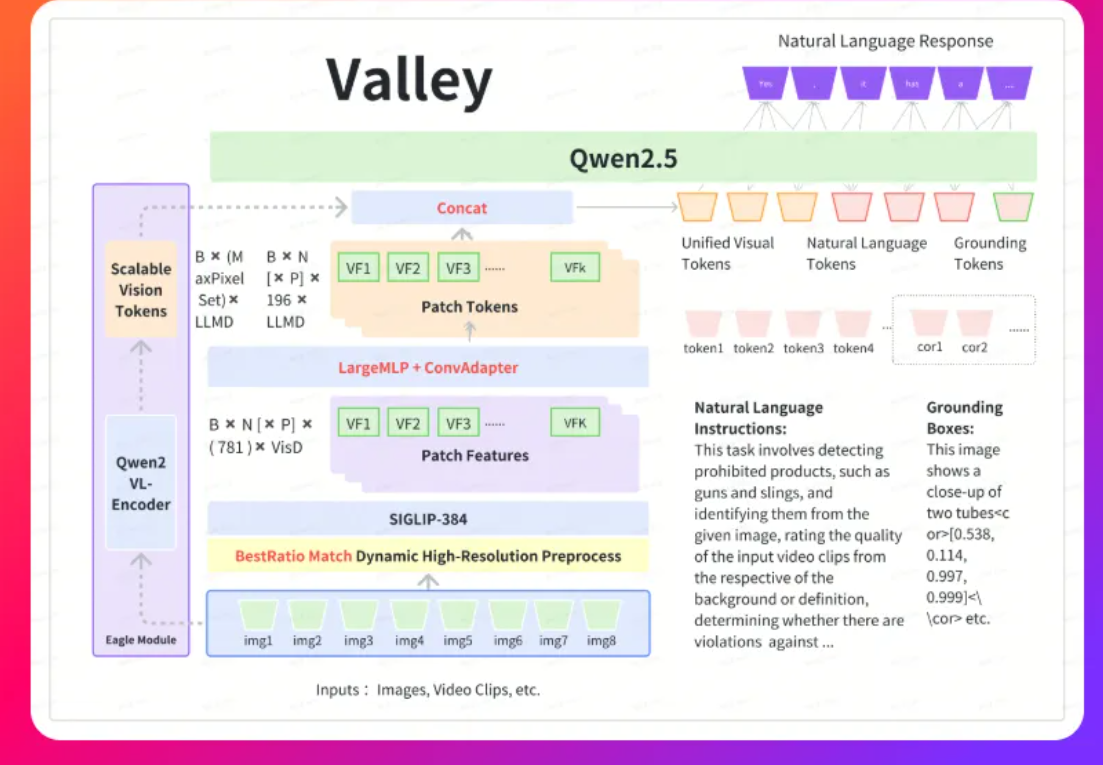
Valley是字节跳动推出的多模态大模型,用于处理涉及文本、图像和视频数据的多样化任务。Valley在内部电子商务和短视频基准测试中取得了最佳成绩,并在OpenCompass测试中展现出色性能,尤其是在小于10B参数规模的模型中排名第二。Valley-Eagle版本基于引入VisionEncoder增强模型在极端场景下的性能,能灵活调整令牌数量,并与原始视觉令牌并行处理。
功能特点
- 多模态数据处理能力:Valley能够处理、融合和理解来自文本、图像、视频等多种模态的数据。
- 视频理解:通过时空池化模块处理多帧视频,实现对视频内容的深入理解和分析。
- 对话生成:可以基于视频、图像内容和用户进行对话,提供个性化的交互体验。
- 指令微调:使用从各种视频任务中收集的多模态指令跟踪数据集进行微调,提升模型的适应性和准确性。
优缺点
-
优点:
- 强大的多模态处理能力:能够处理多种媒体数据,实现跨媒体理解和生成。
- 高效的视频处理能力:通过时空池化模块,实现对视频内容的快速理解和分析。
- 个性化的对话生成:可以根据用户的偏好和需求,生成个性化的输出内容。
-
缺点:
- 数据依赖性强:模型的性能高度依赖于训练数据的质量和多样性。
- 计算资源需求大:多模态大模型的训练和推理需要大量的计算资源和时间。
- 解释性不足:模型的决策过程相对黑盒,难以解释其输出结果的依据。
如何使用
- 数据准备:收集并预处理来自不同模态的数据,如文本、图像、视频等。
- 模型训练:使用准备好的数据进行模型训练,包括预训练和微调阶段。
- 推理应用:将训练好的模型部署到实际应用场景中,进行视频理解、对话生成等任务。
框架结构
- Vision Encoder:使用预训练的CLIP的ViT-L/14作为视觉编码器,提取视频和图像的特征。
- Temporal Modeling Module:通过时序模块对提取的特征进行进一步处理,以捕捉视频中的时序信息。
- Projection Layer:将处理后的特征投影到与LLM一致的嵌入空间中。
- LLM:使用Stable-Vicuna作为大语言模型,处理文本数据并生成输出。
创新点
- 时空池化模块:提出一种时空池化操作来统一视频和图像输入的视觉编码,实现对视频内容的快速理解和分析。
- 多模态指令微调:引入从各种视频任务中收集的多模态指令跟踪数据集进行微调,提升模型的适应性和准确性。
评估标准
- 准确率:衡量模型预测结果与真实结果之间的匹配程度。
- 召回率:衡量模型能够找出多少真实的正例样本。
- F1分数:准确率和召回率的调和平均数,用于综合考虑准确率和召回率的表现。
- 推理速度:衡量模型在处理数据时的速度和效率。
- 鲁棒性:衡量模型在面对噪声、干扰、攻击等异常情况时的稳定性。
应用领域
- 智能客服:提供基于视频、图像内容的对话服务,提升用户体验。
- 视频分析:在视频监控、内容审核等领域进行视频内容的理解和分析。
- 教育转型:通过提供个性化的学习资源和智能化的教学辅助工具,提高教学效果和学习体验。
- 娱乐领域:应用于游戏开发、虚拟偶像等场景,创造更加沉浸式的用户体验。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
