OlympicArena:上海交大联合 AI Lab 等推出的多学科认知推理基准测试框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
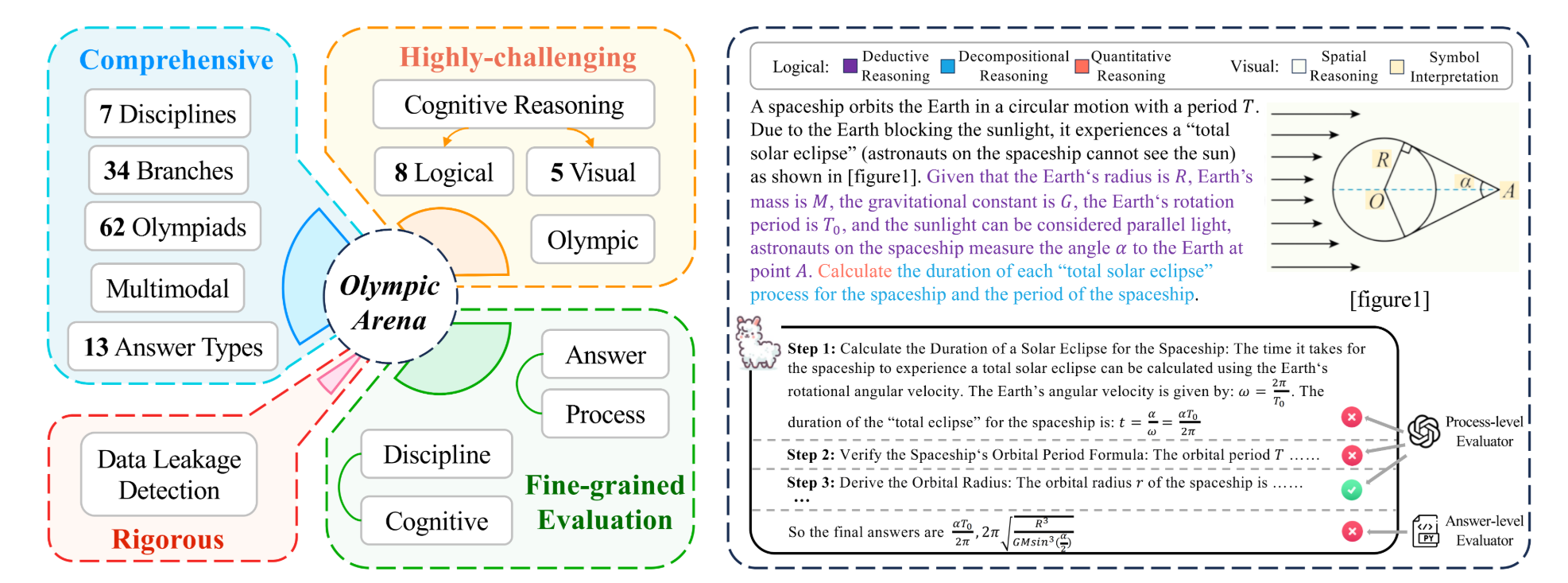
OlympicArena 是由上海交通大学、上海人工智能实验室(上海 AI Lab)等机构联合推出的多学科认知推理基准测试框架。该框架聚焦于评估 AI 系统在复杂认知推理任务中的表现,涵盖数学、物理、化学、生物、地理、天文学、计算机科学等七大学科领域,包含 11,163 道双语(中英文)题目,题目难度对标国际奥林匹克竞赛级别,旨在为 AI 的多学科推理能力提供全面、高难度的评估基准。

功能特点
- 多学科覆盖:涵盖 7 大核心学科及 34 个细分领域,支持跨学科综合推理能力的评估。
- 双语支持:题目提供中英文版本,满足国际化测试需求。
- 细粒度评估:支持答案级和过程级评估,全面检测 AI 的逻辑推理、视觉推理等高级认知能力。
- 多模态处理:包含图文混合题型,测试 AI 的跨模态信息整合能力。
- 防数据泄漏机制:采用 N-gram 技术检测模型是否预先见过测试题目,确保评估的公平性。
优缺点
- 优点:
- 高难度与全面性:题目难度对标国际奥赛,覆盖多学科领域,能有效评估 AI 的复杂推理能力。
- 细粒度评估:支持答案级和过程级评估,提供多维度的性能分析。
- 多模态支持:包含图文混合题型,适应现代 AI 系统处理复杂任务的需求。
- 缺点:
- 计算资源需求高:评估过程需要高性能计算资源,可能限制部分研究者的使用。
- 数据更新周期:题目更新频率可能较低,需定期补充新题以保持挑战性。
如何使用
- 环境配置:克隆仓库并安装依赖,例如通过
git clone https://github.com/GAIR-NLP/OlympicArena.git和pip install -r requirements.txt。 - 数据加载:从 HuggingFace 加载指定学科数据,例如
from datasets import load_dataset; dataset = load_dataset("GAIR/OlympicArena", "Math", split="val")。 - 模型推理:运行推理脚本,指定模型和数据路径,例如
python inference.py --hf_data_path GAIR/OlympicArena --model_output_dir ./model_output/ --split val --model gpt-4o --batch 15。 - 结果评估:执行评估脚本生成详细报告,例如
python evaluation.py --hf_data_path GAIR/OlympicArena --model_output_dir ./model_output/ --result_dir ./result/ --split val --model gpt-4o。
框架技术原理
- 高质量数据构建:从 62 项国际奥赛精选题目,经专业团队多轮分类与标注,确保题目质量。
- 混合评估体系:结合规则匹配、测试用例验证和高性能模型辅助评估,提供全面的性能分析。
- 多模态处理:通过图像识别技术提取视觉信息,生成辅助理解的文本描述,测试 AI 的跨模态能力。
- 防数据泄漏机制:采用 N-gram 技术检测模型是否预先见过测试题目,确保评估的公平性。
创新点
- 多学科交叉设计:题目覆盖多学科领域,揭示 AI 在解决复杂科学问题时的系统性缺陷。
- 细粒度评估机制:支持答案级和过程级评估,全面检测 AI 的逻辑推理和视觉推理能力。
- 多模态处理能力:包含图文混合题型,测试 AI 的跨模态信息整合能力。
- 防数据泄漏机制:采用 N-gram 技术检测模型是否预先见过测试题目,确保评估的公平性。
评估标准
- 答案正确性验证:评估模型答案的正确性。
- 解题过程逻辑性分析:分析模型解题过程的逻辑性和合理性。
- 跨模态信息整合能力:评估模型在图文混合题型中的表现。
- 多学科综合推理能力:评估模型在跨学科题目中的综合推理能力。
应用领域
- AI 模型评估:为 AI 模型提供多学科认知推理能力的评估基准。
- AI 模型优化:通过评估结果指导 AI 模型的优化和改进。
- AI 教育:为 AI 教育提供高难度的练习和测试题目。
- 科学研究:为科学研究提供 AI 模型在复杂推理任务中的表现数据。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
