4月17日·OpenAI发布o3/o4-mini,视觉推理与多模态智能新突破
4月17日·周四 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
OpenAI发布o3/o4-mini,视觉推理与多模态智能新突破
OpenAI推出满血版o3和下一代推理模型o4-mini,两款模型首次将图像推理融入思维链,实现了“用图像思考”,在视觉推理领域达到新高度。o3以十倍于o1的算力,在编程、数学、视觉感知等基准测试中刷新SOTA,表现接近“天才水平”,尤其在图像、图表分析方面优势突出。o4-mini则以小巧高效、高性价比著称,在AIME 2025测试中配合Python解释器取得99.5%高分,性能全面优于o3-mini。此外,OpenAI还开源了轻量级编程AI智能体Codex CLI,支持本地代码部署与多模态推理。两款模型通过强化学习训练,掌握工具使用智慧,能自主调用工具解决复杂任务,为多模态智能应用带来新机遇。来源:微信公众号【新智元】
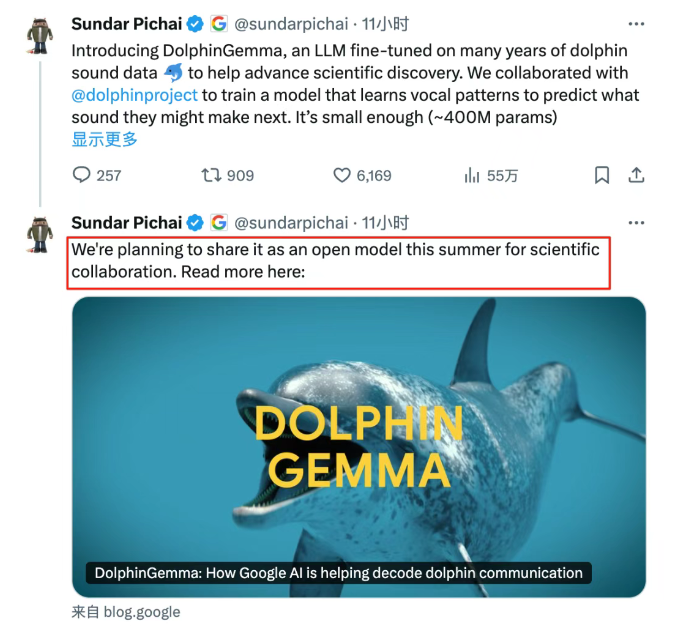
谷歌AI模型DolphinGemma开启人类与海豚的跨物种交流
谷歌推出了一款名为DolphinGemma的AI模型,致力于破解海豚的语言密码。该模型基于30年海豚研究数据训练而成,仅有400M参数,可在普通Pixel手机上运行。DolphinGemma能够识别海豚的声音模式,并预测它们的下一个发声,类似于LLM预测下一个词。谷歌CEO Sundar Pichai表示,这标志着人类跨物种交流的重大突破。该模型利用Google的音频技术SoundStream分词器,高效地表示海豚声音,并通过模型架构处理复杂序列。DolphinGemma基于Gemma构建,采用与Gemini相同的研发技术,能够处理自然海豚声音序列,识别模式并预测后续声音。此外,DolphinGemma还将与佐治亚理工学院合作开发的水下计算机CHAT系统结合,进一步推动与海豚的实时交流。这一创新不仅展示了AI在跨物种交流中的潜力,也为未来与更多动物的交流提供了可能。来源:微信公众号【新智元】
豆包1.5·深度思考模型上线,开启多模态推理新时代
火山引擎在杭州举办的Force Link AI创新巡展上宣布,豆包1.5·深度思考模型正式上线。该模型包含两个版本:Doubao-1.5-thinking-pro和具备多模态能力的视觉版Doubao-1.5-thinking-pro-vision。前者在数学推理、编程竞赛、科学推理等专业领域表现出色,后者则支持视觉推理,能够结合文本和图像信息解决复杂问题。豆包1.5·深度思考模型采用MoE架构,总参数达200B,激活参数仅20B,具备显著的训练和推理成本优势。其低延迟特性(20毫秒)和强大的深度思考能力使其在多个场景中表现出色。此外,豆包大模型家族的其他成员也迎来升级,如豆包·视觉理解模型和豆包文生图模型3.0版本,进一步提升了视觉定位、视频搜索和图像生成能力。火山引擎还发布了OS Agent解决方案、GUI Agent大模型和AI云原生推理套件,助力企业高效落地AI应用。来源:微信公众号【机器之心】

大连理工&莫纳什大学提出物理合理视频生成框架VLIPP
大连理工和莫纳什大学的研究团队提出了一种物理合理的视频生成框架VLIPP,旨在解决现有视频扩散模型(VDMs)生成视频不符合物理规律的问题。该框架通过将视觉语言模型(VLM)与视频扩散模型相结合,引入物理约束,显著提升了视频生成的物理真实性。具体而言,VLIPP分为两个阶段:第一阶段利用VLM作为粗粒度的运动规划器,预测物理可能的运动路径;第二阶段通过视频扩散模型根据预测路径生成细粒度的运动序列。实验结果表明,该框架在多个物理场景的视频生成任务中表现优异,尤其是在机械运动、流体运动和热力学等领域。这一成果不仅证明了将语言模型的物理知识引入扩散模型的可行性,也为视频扩散模型作为世界模拟器的应用带来了新的可能性。来源:微信公众号【机器之心】

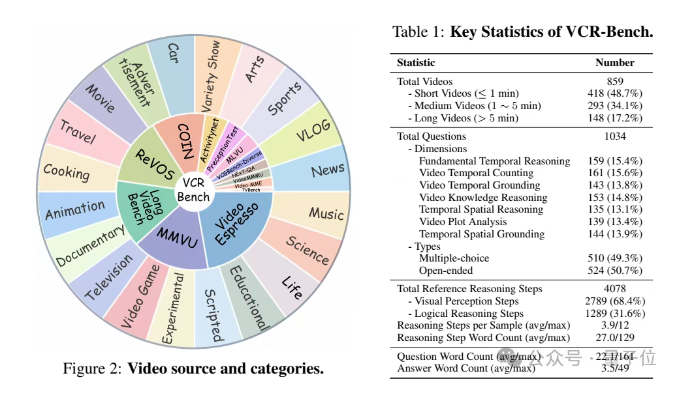
中科大等团队发布视频CoT推理能力评估基准VCR-Bench
中科大等团队提出了首个面向视频CoT(Chain-of-Thought,思维链)推理能力的多模态评估基准VCR-Bench。该基准包含七个独立评估维度的任务框架,涵盖时空推理、因果推断等能力,每个维度设计了100余条高质量样本,形成大规模数据集。研究发现,当前多模态模型在视频复杂推理任务上表现普遍不佳,最优模型o1仅获得62.8的CoT得分和56.7%的准确率,大多数模型两项指标均低于40分。实验结果表明,视觉感知能力不足是制约模型性能提升的首要因素,而时空定位(TSG)维度表现最差。此外,模型的CoT得分和准确率高度正相关,中等长度视频表现最佳。VCR-Bench为视频理解模型的推理能力评估提供了标准化方法,填补了现有研究的不足。来源:微信公众号【机器之心】
相关文章
