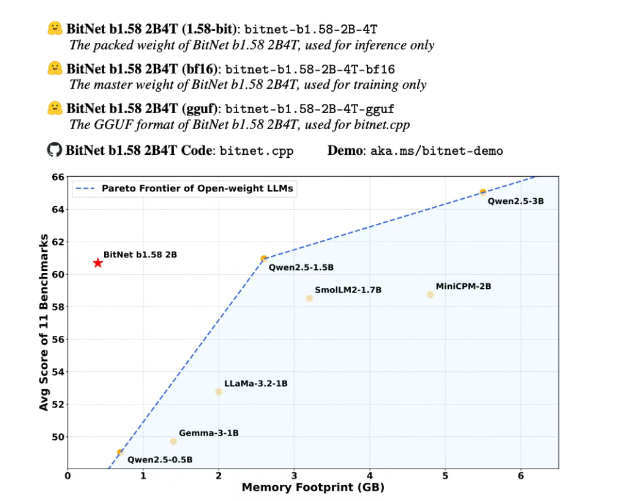
4月19日·微软开源首个原生1bit模型BitNet,仅需0.4GB,性能媲美全精度模型
4月19日·周六 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
微软开源首个原生1bit模型BitNet,仅需0.4GB,性能媲美全精度模型
微软研究院开源了一款原生1bit精度的大语言模型BitNet b1.58 2B4T。该模型参数量为20亿,仅包含{-1, 0, +1}三种数值,模型大小仅为0.4GB,可在CPU上高效运行。BitNet通过创新的推理框架,突破了内存限制,同时在多项基准测试中表现优异,与全精度模型相当。它在语言理解、数学推理、编码熟练度和对话能力等任务上均进行了严格评估,展现出显著的资源效率和竞争力。此外,BitNet还提供了针对GPU和CPU的开源推理实现,为端侧AI部署开启了新的可能性。来源:微信公众号【新智元】
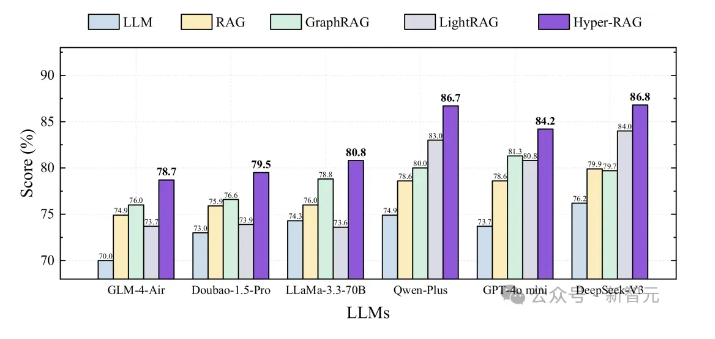
清华提出Hyper-RAG,用超图提升知识建模精准度,让DeepSeek更可靠
清华大学联合西安交通大学等机构提出了Hyper-RAG(超图驱动的检索增强生成方法),旨在通过超图表征提升大语言模型(LLM)的知识建模精准度,减少幻觉现象。Hyper-RAG利用超图同时捕捉原始数据中的低阶和高阶关联信息,最大限度减少知识结构化过程中的信息丢失。实验表明,Hyper-RAG在多个领域数据集上显著提升了LLM的准确率,平均提升12.3%,并保持在复杂查询下的稳定性能。此外,其轻量级变体Hyper-RAG-Lite在检索速度上达到Light RAG的两倍,性能提升3.3%。该方法为医疗诊断、金融分析等高可靠需求应用提供了有力支撑。来源:微信公众号【新智元】
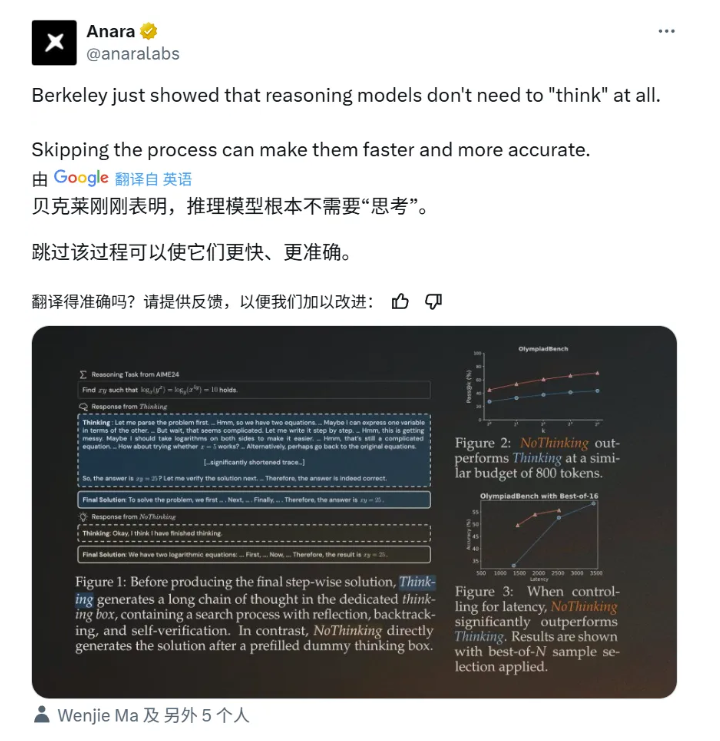
伯克利研究发现:推理模型跳过“思考”过程会更快、更准确
加州大学伯克利分校和艾伦人工智能研究所的一项新研究提出,推理模型在生成答案时跳过显式思考过程(NoThinking),可能会比传统思考过程(Thinking)更高效且更准确。研究发现,在控制 token 使用量的情况下,NoThinking 方法在多样本准确率(pass@k)方面显著优于 Thinking 方法,且在低预算设置下表现更好。实验表明,NoThinking 方法在多个基准测试中,尤其是在数学和编程任务上,能够以更少的 token 使用量达到与 Thinking 方法相当甚至更高的准确率。此外,NoThinking 方法结合并行采样策略,能够在显著降低延迟的情况下,实现与传统顺序方法相似甚至更好的推理性能。该研究为高效推理模型的设计提供了新的思路,质疑了冗长思考过程的必要性。来源:微信公众号【机器之心】
英特尔发布具身智能大小脑融合方案,推动具身智能落地
英特尔在2025年4月18日的推介会上正式发布了具身智能大小脑融合方案。该方案基于英特尔®酷睿™ Ultra处理器的强大算力,结合全新的具身智能软件开发套件和AI加速框架,通过模块化设计实现了操作精度与智能泛化能力的兼顾。其核心亮点是大小脑融合架构,通过CPU、集成GPU和NPU的协同运行,支持具身智能的多样化负载,大幅提升系统效率和响应能力。此外,英特尔还推出了具身智能软件开发套件,支持一次开发多平台部署,简化方案搭建过程,加快产品上市。英特尔还与生态伙伴合作,如信步科技和浙江人形机器人创新中心,推动具身智能在工业和服务场景中的应用。该方案凭借其创新架构,成为具身智能系统落地的理想选择,未来有望拓展至医疗、教育、养老等更多领域。来源:微信公众号【机器之心】

通义Wan2.1首尾帧视频模型发布,轻松生成丝滑视频
相关文章
