4月28日·北京大学推出 PHYBench:大模型物理推理能力“试金石”
4月28日·周一 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
北京大学推出 PHYBench:大模型物理推理能力“试金石”
北京大学物理学院联合多个院系,发布了全新物理评测基准 PHYBench。该项目由朱华星老师、曹庆宏副院长指导,汇聚了 200 余名学生,其中包括 50 多位物理竞赛金牌得主。PHYBench 包含 500 道涵盖高中到物理竞赛难度的高质量物理题,采用创新的“表达式树编辑距离”评分法,能更精准地评估模型的物理感知与推理能力。实验显示,最强 AI 模型 Gemini 2.5 pro 在该基准上正确率仅为 36.9%,远低于人类专家的 61.9%。该基准不仅为大模型的物理推理能力提供了权威评测工具,也为 AI 的未来发展指明了方向。来源:微信公众号【机器之心】
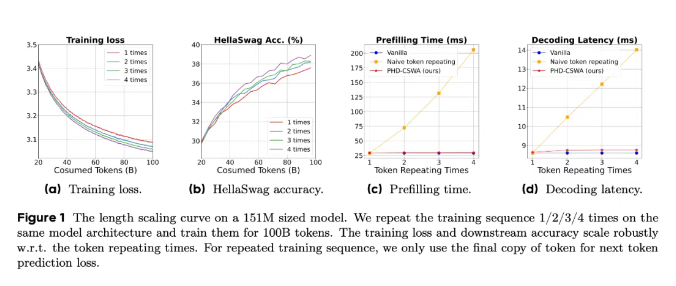
字节 Seed 团队提出 PHD-Transformer,突破预训练长度扩展瓶颈
字节跳动 Seed 团队近期在预训练长度扩展领域取得重大突破,提出 PHD-Transformer 架构。该架构通过创新的 KV 缓存管理策略,解决了传统方法中 KV 缓存膨胀、推理延迟增加等问题。PHD-Transformer 通过仅保留原始 token 的 KV 缓存,并在隐藏解码 token 预测后丢弃其缓存,实现了与原始 Transformer 相同的缓存大小,同时显著提升了推理速度。此外,团队还引入了 PHD-SWA 和 PHD-CSWA 等改进方法,进一步优化性能。实验表明,PHD-CSWA 在多个基准测试中平均准确率提升 1.5% 至 2.0%,训练损失显著降低。该研究为大模型的高效预训练提供了新的思路。来源:微信公众号【机器之心】
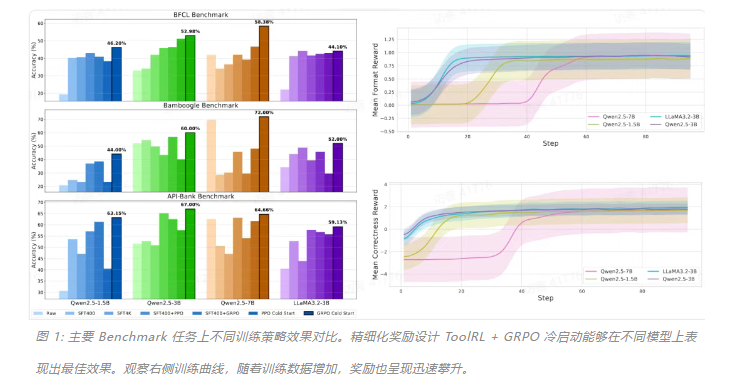
ToolRL:首个系统性工具使用奖励范式,革新大模型训练思路
伊利诺伊大学香槟分校研究团队提出了 ToolRL,一种基于强化学习范式的工具使用训练方法。该方法通过精细化的奖励设计,解决了大语言模型在工具推理中的泛化难题。ToolRL 将工具调用建模为 Tool-Integrated Reasoning(TIR)任务,强调多步交互、组合调用和推理驱动。实验表明,ToolRL 训练的模型在多个基准测试中准确率显著提升,平均超过 15%,并且展现出更强的泛化能力和更合理的工具调用策略。该研究不仅提出了一种新方法,还开创了基于工具调用的强化学习奖励新范式,为大模型与外部工具协同提供了更灵活的训练思路。来源:微信公众号【机器之心】
第三方团队推出 DeepSeek-R1T-Chimera,融合 R1 与 V3 实现高效推理
坊间传闻 DeepSeek 即将发布 R2,但等不及官方的开源社区已经行动起来。德国团队 TNG Technology Consulting 推出了基于 DeepSeek V3-0324 和 R1 融合的新模型 DeepSeek-R1T-Chimera。该模型结合了 R1 的推理能力和 V3-0324 的高效性,推理速度更快,输出 token 减少 40%。实验表明,R1T-Chimera 在处理复杂问题(如“7 米甘蔗过 2 米门”)时,推理过程更紧凑有序,最终通过计算夹角与投影得出正确结论。该模型已开放权重,可在 HuggingFace 下载或在 OpenRouter 在线试玩。这一尝试引发了对模型融合技术的关注,未来可能成为大模型发展的一大趋势。来源:微信公众号【机器之心】
阶跃星辰发布多款多模态模型,大模型行业加速进入“多模态时间”
多模态技术正在成为全球 AI 大模型发展的核心趋势,阶跃星辰在过去一个月内接连发布了 3 款多模态模型:Step1X-Edit 图像编辑模型、Step-R1-V-Mini 多模态推理模型和 Step-Video-TI2V 图生视频模型。其中,Step1X-Edit 总参数量 19B,采用 MLLM 与 DiT 解耦式架构,首次在开源体系中实现这一创新,性能达到开源 SOTA 水平。Step-R1-V-Mini 则在视觉推理榜单 MathVision 中位列国内第一,展现了强大的推理能力。这些模型的发布不仅体现了阶跃在多模态领域的快速迭代能力,也标志着大模型行业正在加速进入“多模态时间”,多模态技术成为 AI 应用落地的关键要素。来源:微信公众号【量子位】

相关文章
