Absolute Zero:清华大学等机构推出的语言模型推理训练方法
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
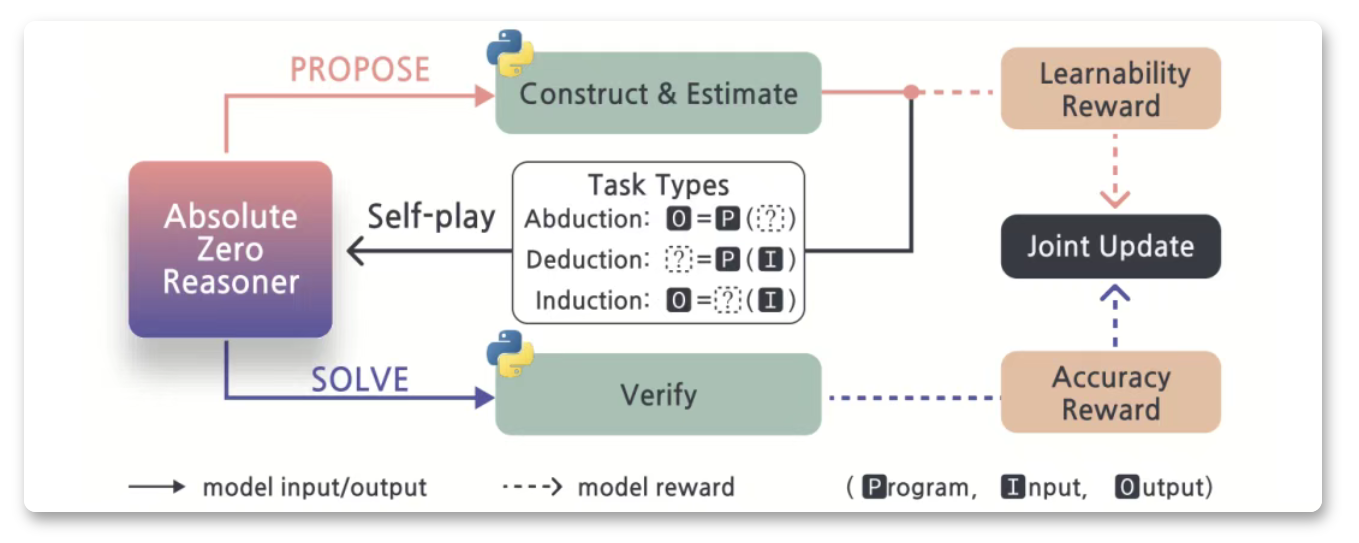
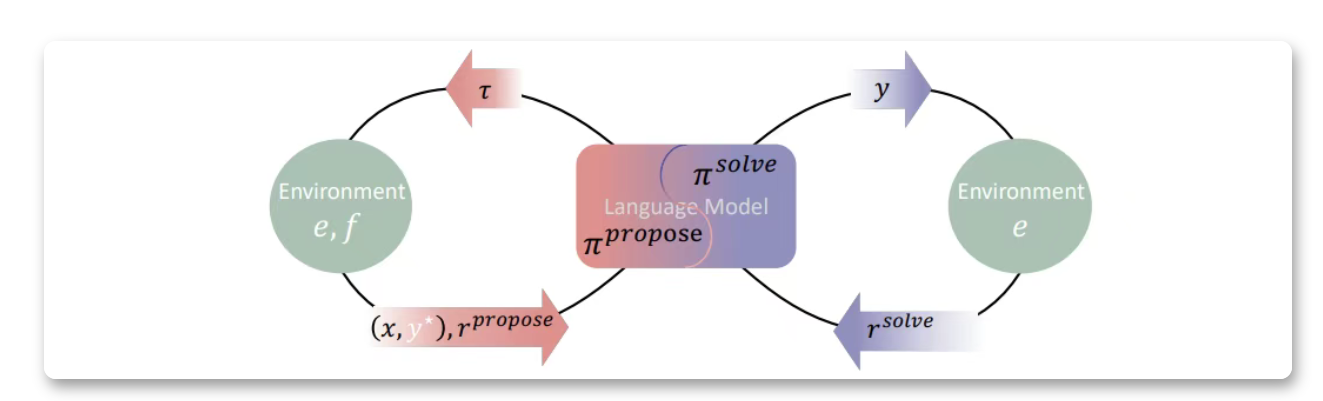
Absolute Zero 是由清华大学 LeapLab 团队、北京通用人工智能研究院 NLCo 实验室和宾夕法尼亚州立大学联合提出的一种全新的语言模型推理训练范式。该范式旨在解决传统大模型训练对人工标注数据的依赖问题,通过让模型自主提出任务并自我解决,实现“零数据”条件下的推理能力提升。其核心思想是通过自博弈(self-play)机制,使模型在与环境的交互中生成可验证的任务,并从中获得反馈以不断优化自身推理能力。

功能特点
- 零数据依赖:无需人类或 AI 生成的数据任务,模型通过自我提出任务并自主解决,实现推理能力的自我进化。
- 自博弈闭环:模型同时担任任务提出者(Proposer)和求解者(Solver),通过与环境的交互生成可验证的任务并获得反馈。
- 支持多种推理模式:涵盖归纳推理、演绎推理和溯因推理,适用于代码生成、数学推理等跨领域任务。
- 环境可验证反馈:通过代码执行器等环境验证任务的合理性和解答的正确性,确保训练的稳定性和可靠性。
- 高效的任务设计能力:模型能够生成具有中等难度的任务,避免过于简单或过于困难的任务,从而最大化学习效率。
优缺点
- 优点:
- 完全摆脱人工数据依赖:显著缓解了高质量人工数据获取的难题,降低了训练成本。
- 自主进化能力:模型通过自博弈机制不断提出新任务并解决,推理能力持续提升。
- 跨领域迁移能力:在代码生成与数学推理等跨领域基准任务中表现出色,超越了传统方法。
- 高灵活性:支持多种推理模式,适用于不同场景的任务需求。
- 缺点:
- 训练复杂度高:自博弈机制需要模型同时具备任务提出和求解能力,增加了训练的难度和计算资源需求。
- 环境依赖性强:模型的训练依赖于可验证反馈的环境(如代码执行器),在缺乏合适环境的场景中可能受限。
- 可解释性挑战:自博弈过程中模型生成的任务和解答可能缺乏直观的可解释性,增加了调试和优化的难度。
如何使用
- 环境准备:
- 安装 Python 代码执行器或其他可验证反馈的环境,用于验证模型生成的任务和解答。
- 模型初始化:
- 克隆项目仓库:
git clone https://github.com/leaplab-tsinghua/absolute-zero.git - 安装依赖库(如 PyTorch、Hugging Face Transformers 等)。
- 克隆项目仓库:
- 训练配置:
- 配置训练参数(如任务类型、奖励函数、学习率等)。
- 示例配置文件:
yaml
model_name: “gpt2-large” task_types: [“deduction”, “induction”, “abduction”] reward_function: “learnability_and_accuracy” learning_rate: 1e-5 batch_size: 32
- 模型训练:
- 运行训练脚本:
python train.py --config configs/absolute_zero.yaml - 模型将通过自博弈机制不断提出任务并解决,同时根据环境反馈优化自身策略。
- 运行训练脚本:
- 推理与评估:
- 使用训练好的模型进行推理,输入任务描述,模型将生成解答。
- 评估指标包括准确性、鲁棒性和经济性(单位推理成本)。
框架技术原理
- 自博弈机制:
- 模型在每轮训练中首先提出一批新任务,并通过环境验证其可解性与学习价值。
- 随后模型尝试解决这些任务,并根据答案的正确性获得奖励。
- 模型结合“可学习性奖励”和“解答奖励”更新参数,实现多任务下的自我进化学习。
- 奖励函数设计:
- 可学习性奖励:鼓励模型提出具有中等难度的任务,定义为
1 - 平均准确率(当准确率为 0 或 1 时奖励为 0)。 - 解答奖励:若模型给出的答案与标准答案完全一致,奖励为 1,否则为 0。
- 可学习性奖励:鼓励模型提出具有中等难度的任务,定义为
- 环境交互:
- 模型提出任务后,环境(如代码执行器)验证其可执行性、输出是否正确、是否具有确定性,确保任务是有效且可用的。
创新点
- 零数据训练范式:
- 首次提出完全不依赖人工数据的训练方法,通过自博弈机制实现模型的自我进化。
- 自博弈闭环设计:
- 模型同时担任任务提出者和求解者,通过与环境交互生成可验证的任务并获得反馈,形成闭环学习。
- 多任务支持:
- 支持归纳推理、演绎推理和溯因推理等多种推理模式,适用于跨领域任务。
- 高效的任务设计能力:
- 模型能够生成具有中等难度的任务,最大化学习效率,避免资源浪费。
评估标准
- 准确性:
- 使用 F1-score@K 等指标评估模型生成解答的准确性。
- 鲁棒性:
- 通过对抗样本通过率等指标评估模型在面对噪声或干扰时的稳定性。
- 经济性:
- 计算单位推理成本(如 TOPS/$),评估模型的计算效率。
- 跨领域迁移能力:
- 在代码生成、数学推理等跨领域基准任务中评估模型的性能。
应用领域
- 代码生成与自动化编程:
- 自动生成可执行的代码片段,辅助开发者提高效率。
- 数学推理与问题求解:
- 解决复杂的数学问题,支持教育、科研等领域的应用。
- 智能客服与自动化问答:
- 通过零数据训练实现高效的推理能力,提升客服系统的响应质量。
- 游戏 AI 与智能体设计:
- 通过自博弈机制训练智能体,提升其在复杂环境中的决策能力。
项目地址
- GitHub 仓库:https://github.com/leaplab-tsinghua/absolute-zero
- 项目主页:https://leaplab-tsinghua.github.io/absolute-zero/
Absolute Zero 的提出为语言模型训练提供了一种全新的思路,其零数据依赖和自博弈机制为模型的自主进化提供了可能,具有广阔的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
