EMOVA —— 华为诺亚方舟联合多所高校共同推出的多模态全能处理模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
EMOVA的主要介绍
EMOVA(EMotionally Omni-present Voice Assistant)是华为诺亚方舟实验室联合多所高校共同推出的多模态全能处理模型,旨在实现更自然、更智能的人机交互。EMOVA是一种创新的全模态大型语言模型,旨在实现视觉、语言和语音的端到端处理。它不仅能够处理图像、文本和语音数据,还具备丰富的情感表达能力。通过语义-声学解耦的语音标记器、全模态对齐和轻量级风格模块,EMOVA在视觉-语言和语音基准测试中表现出色,适用于智能助手、虚拟现实、教育和娱乐等领域。

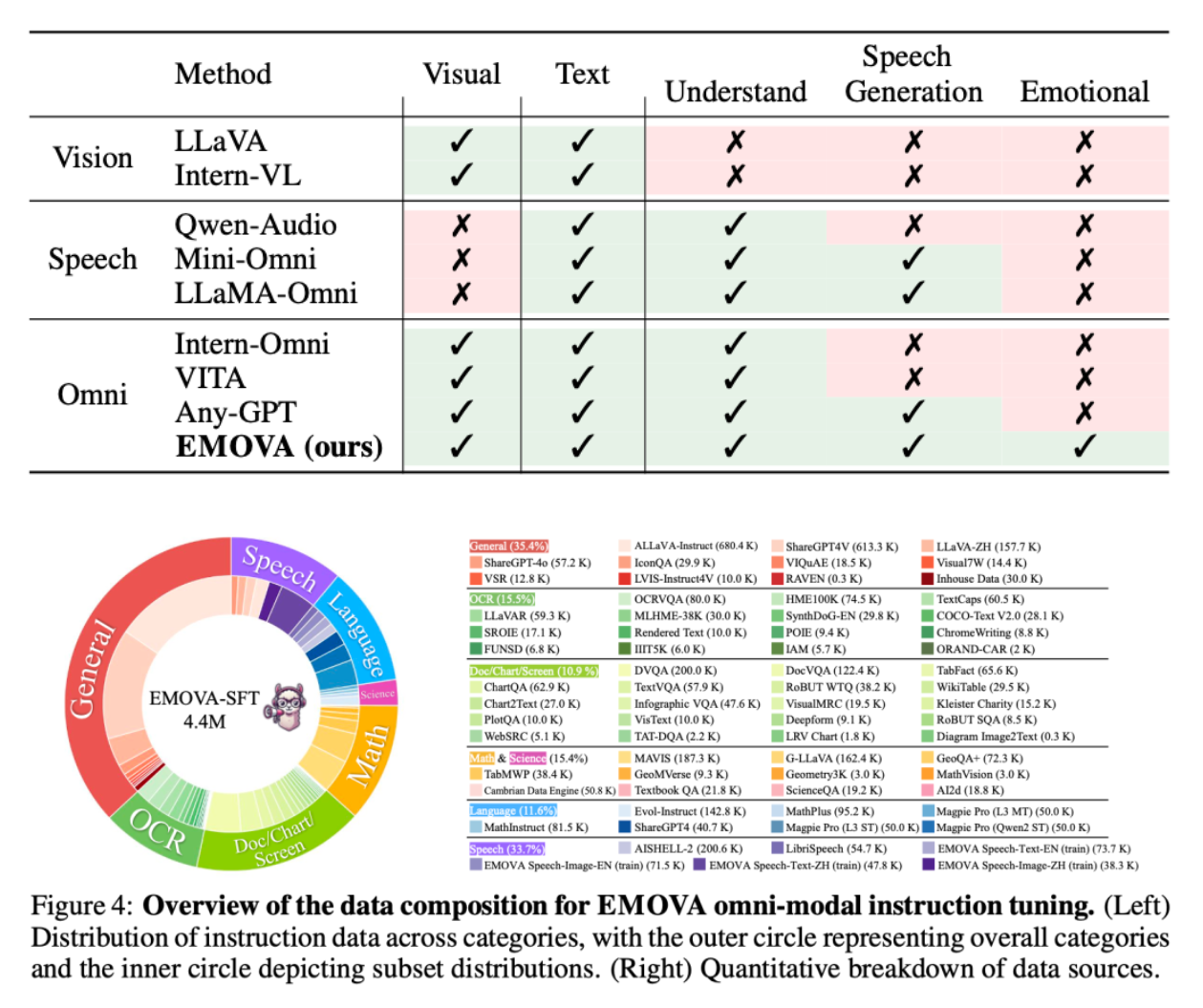
EMOVA的功能特点
- 多模态处理能力:EMOVA能够同时处理图像、文本和语音模态的数据,实现全模态的端到端处理。
- 情感丰富的语音交流:通过语义-声学解耦的语音标记器和轻量级风格模块,EMOVA能够生成情感丰富、自然流畅的语音,提升人机交互体验。
- 高效的跨模态对齐:EMOVA提出了数据高效的全模态对齐方法,利用文本作为桥梁,避免了全模态图文音训练数据的匮乏问题,并通过联合优化进一步增强了模型的跨模态能力。
- 优越的性能表现:在多个图像文本、语音文本的基准测试中,EMOVA展现了优越的性能,特别是在复杂的视觉和语音任务中表现出色。
EMOVA的优缺点
优点:
- 多模态处理能力:能够同时处理图像、文本和语音数据,实现全模态交互。
- 情感丰富的语音交流:提升人机交互的自然度和舒适度。
- 高效的跨模态对齐:降低数据需求,提高模型训练效率。
缺点:
- 计算资源和数据需求大:EMOVA的训练和部署需要大量的计算资源和数据支持,可能限制其在资源受限环境中的应用。
- 实际应用中的复杂性:尽管在基准测试中表现出色,但在实际应用中可能面临各种复杂情况和挑战。
如何使用EMOVA
目前,关于EMOVA的具体使用方法尚未公开。但一般来说,使用此类多模态处理模型通常涉及数据准备、模型训练、多模态输入处理和结果分析等步骤。用户可能需要根据官方文档或研究团队的指导来进行操作。
EMOVA的框架结构
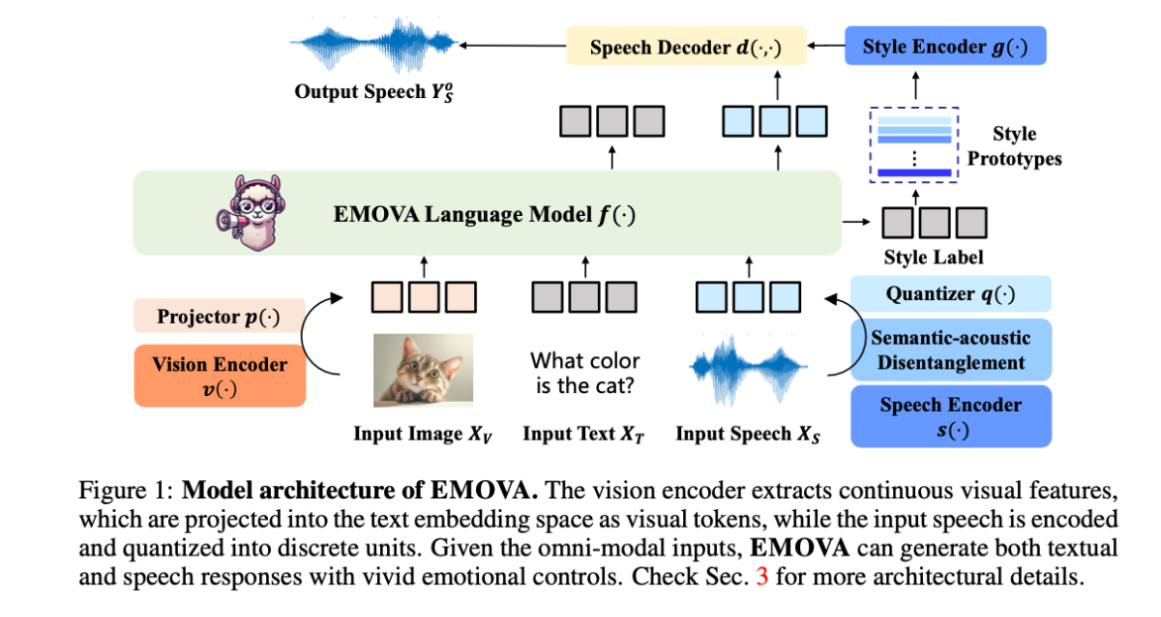
EMOVA的框架结构结合了连续的视觉编码器和离散的语音分词器,能够将输入的图像、文本和语音信息进行高效处理,并端到端生成文本和带情感的语音输出。以下是其架构的几个关键点:
- 视觉编码器:采用连续的视觉编码器捕捉图像的精细视觉特征,保证领先的视觉语言理解性能。
- 语音分词器:采用语义声学分离的语音分词器将语音分解为语义内容(语音所表达的意思)和声学风格(语音的情感、音调等),降低语音模态的合入难度并为个性化语音生成和情感注入提供灵活度。
- 情感控制模块:引入轻量级的风格模块支持对语音情感(如开心、悲伤等)、说话人特征(如性别)、语速、音调的控制,在保持语义不变的情况下动态调节语音输出的风格。
EMOVA的创新点
- 全模态处理能力:EMOVA是首个能够在保持视觉文本和语音文本性能领先的同时支持带有情感的语音对话的模型。
- 语义-声学解耦的语音标记器:通过解耦语音的语义内容和声学风格,实现更灵活和精确的语音生成和控制。
- 数据高效的全模态对齐方法:利用文本作为桥梁实现全模态对齐,降低数据需求并提高模型训练效率。
EMOVA的评估标准
EMOVA的评估标准主要基于其在视觉、语言和语音任务上的性能表现。这包括图像识别、文本理解、语音识别、语音合成等多个方面的测试。通过对比实验和基准测试,可以评估EMOVA在处理多模态数据时的准确性、效率和情感表达能力。
EMOVA的应用领域
EMOVA的应用领域非常广泛,包括但不限于智能助手、虚拟现实、教育和娱乐等领域。它可以用于实现更自然、更智能的人机交互体验,提升用户在使用各种设备和服务时的满意度和效率。
EMOVA的项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
