SearchAgent-X : 南开等机构推出的高效推理框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
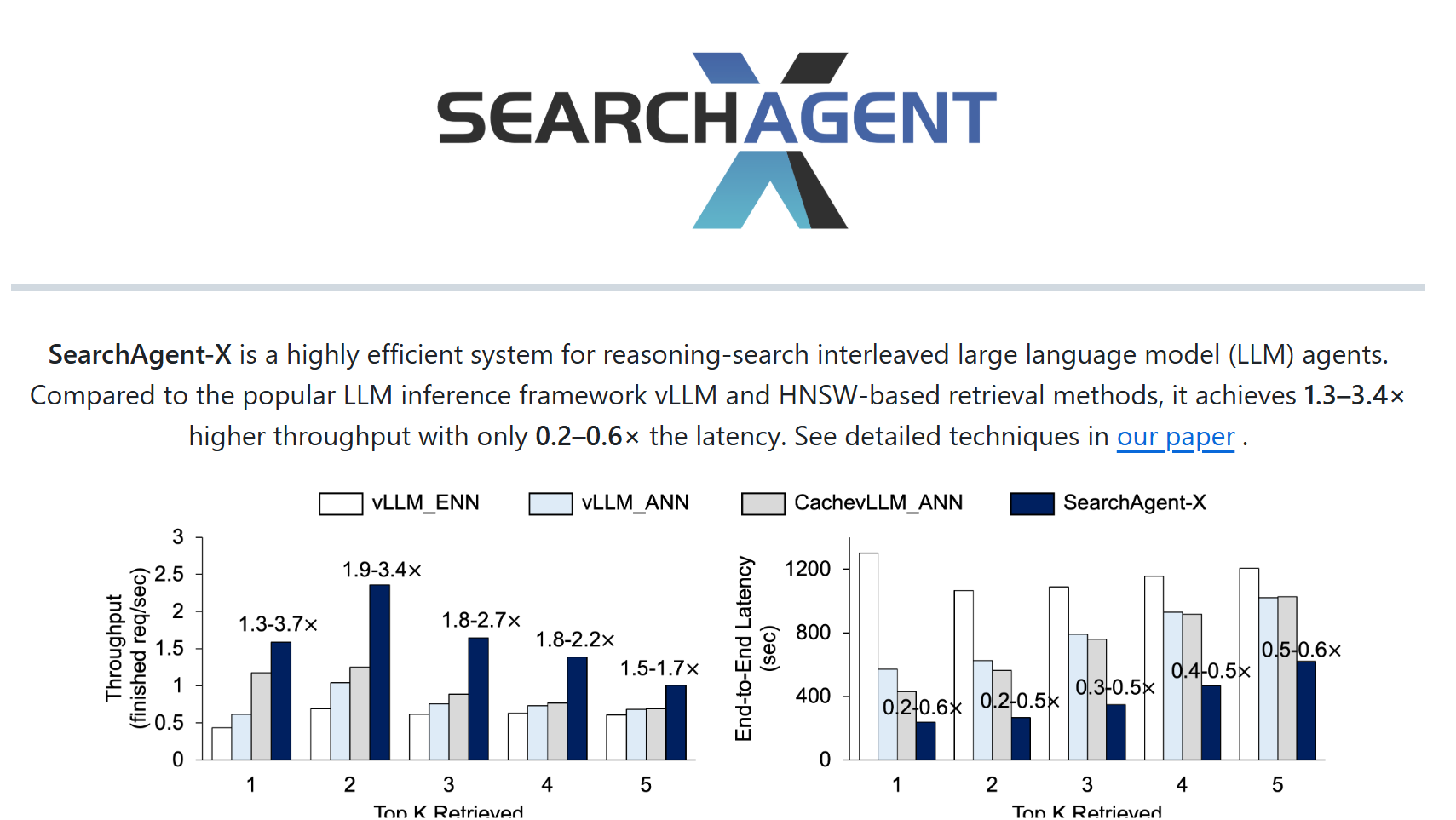
SearchAgent-X是由南开大学与伊利诺伊大学厄巴纳-香槟分校(UIUC)联合研发的高效推理框架,专为提升大语言模型(LLM)驱动的搜索智能体性能而设计。该框架通过智能调度与自适应检索机制,解决传统搜索智能体在复杂任务中效率低下、延迟高的问题,实现吞吐量提升1.3至3.4倍,延迟降低至原来的1/1.7至1/5,同时保持答案质量不下降。其核心目标是为搜索引擎、企业问答系统等复杂AI Agent提供高效、低延迟的推理解决方案,推动AI与外部知识库交互的效率革命。
功能特点
- 优先级感知调度
- 动态排序并发请求,根据检索次数、上下文长度和等待时间分配计算资源,减少无谓等待与重复劳动,提升KV缓存利用率。
- 无停顿检索
- 允许生成过程在检索结果“足够好”时继续进行,避免不必要的等待,同时确保检索信息质量。
- 高召回率的近似检索
- 在保证召回足够有用信息的前提下,控制单次检索开销,避免过高精度检索带来的计算资源消耗。
- 多轮推理支持
- 监控模型输出中的检索信号,暂停解码并发出查询,将检索结果与已生成内容拼接,形成扩展序列后继续推理。
- 前缀缓存技术
- 存储LLM注意力机制中已处理token的键值对,支持多轮交互中的高效复用,减少重复计算。
优缺点
优点
- 高吞吐量与低延迟:实现吞吐量显著提升,延迟大幅降低,尤其在高并发场景下优势明显。
- 资源利用率高:通过智能调度与缓存复用,最大化GPU资源利用率,减少KV缓存未命中率。
- 答案质量保障:在提升效率的同时,不牺牲生成答案的质量,甚至在某些数据集上准确率略有提升。
缺点
- 依赖近似检索:高召回率的近似检索可能在极少数情况下遗漏关键信息,需结合具体应用场景评估。
- 实现复杂度高:涉及智能调度、自适应检索等多项技术,对开发者的技术能力要求较高。
如何使用
- 环境配置
- 安装依赖库(如PyTorch、vLLM等),配置GPU环境。
- 模型加载
- 加载预训练的大语言模型(如Qwen-7B/14B)。
- 集成SearchAgent-X
- 将框架的优先级感知调度与无停顿检索机制集成至现有推理流程。
- 调用API
- 通过框架提供的API接口,发起检索与推理请求,处理返回结果。
- 性能调优
- 根据具体任务调整调度策略与检索参数,优化吞吐量与延迟。
框架技术原理
- 智能调度机制
- 基于请求的实时状态动态调整处理优先级,确保长任务与短任务的合理分配,避免KV缓存被“挤掉”。
- 自适应检索策略
- 根据检索结果的成熟度与LLM引擎的就绪状态,灵活终止检索过程,减少不必要的等待。
- 多轮推理与检索交错
- 在生成过程中动态插入检索步骤,通过序列拼接与前缀缓存技术,实现高效的知识库交互。
- 迭代级调度
- 在单个token生成步骤的粒度上进行GPU调度决策,避免GPU空闲,提升系统吞吐量。
创新点
- 系统级协同设计
- 从整体工作流角度优化搜索智能体,而非单一环节,实现效率与质量的双重提升。
- 优先级感知与无停顿检索
- 通过智能调度与自适应机制,解决传统系统中因不当调度与检索停滞导致的效率问题。
- 高召回率近似检索
- 在保证检索质量的前提下,控制单次检索开销,避免过高精度检索带来的性能损耗。
评估标准
- 吞吐量
- 衡量系统在单位时间内处理的请求数量,SearchAgent-X实现1.3至3.4倍的提升。
- 延迟
- 测量从请求发起到返回结果的时间,SearchAgent-X将延迟降低至原来的1/1.7至1/5。
- 答案质量
- 通过生成准确率等指标评估答案质量,确保效率提升不以牺牲质量为代价。
- 资源利用率
- 监测GPU利用率、KV缓存命中率等指标,评估系统对计算资源的利用效率。
应用领域
- 搜索引擎
- 提升搜索结果的生成效率与质量,优化用户体验。
- 企业问答系统
- 加速内部知识库的检索与推理过程,提高员工工作效率。
- 智能客服
- 实现低延迟、高准确率的自动问答,降低人力成本。
- 学术研究
- 为复杂问题的推理与检索提供高效工具,加速科研进程。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
