Tora —— 阿里推出的AI视频生成框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Tora的介绍
Tora是阿里巴巴推出的一款AI视频生成框架,它以轨迹为导向,整合了广泛的视觉和轨迹指令,能够生成高质量、可控运动的视频内容。Tora 的设计与 DiT 的可扩展性无缝契合,允许精确控制具有不同持续时间、宽高比和分辨率的视频内容。大量实验证明,Tora 在实现高运动保真度方面表现出色,同时还能细致模拟物理世界的运动。

Tora的特点和功能
- 轨迹导向的DiT框架:Tora是首个轨迹导向的Diffusion Transformer(DiT)视频生成框架。它整合了广泛的视觉和轨迹指令,能够熟练地创建可操控运动的视频。
- 可扩展性:为了与DiT的可扩展性保持一致,Tora设计了一种新颖的轨迹提取器和运动引导融合机制。这使得Tora能够根据任意数量的物体轨迹、图像和文本条件生成不同分辨率和时长的视频。
- 高分辨率视频生成:Tora能够生成具有不同纵横比的720p分辨率视频,最长可达204帧,所有这些都由指定的轨迹引导。
- 精确的运动控制:Tora在模拟物理世界中的运动方面表现出色,其生成的运动更加平滑,并且更符合物理世界。通过自适应归一化层,将多层次的运动特征引入到相应的DiT块中,确保生成的视频始终遵循预定义的轨迹。
Tora的技术细节
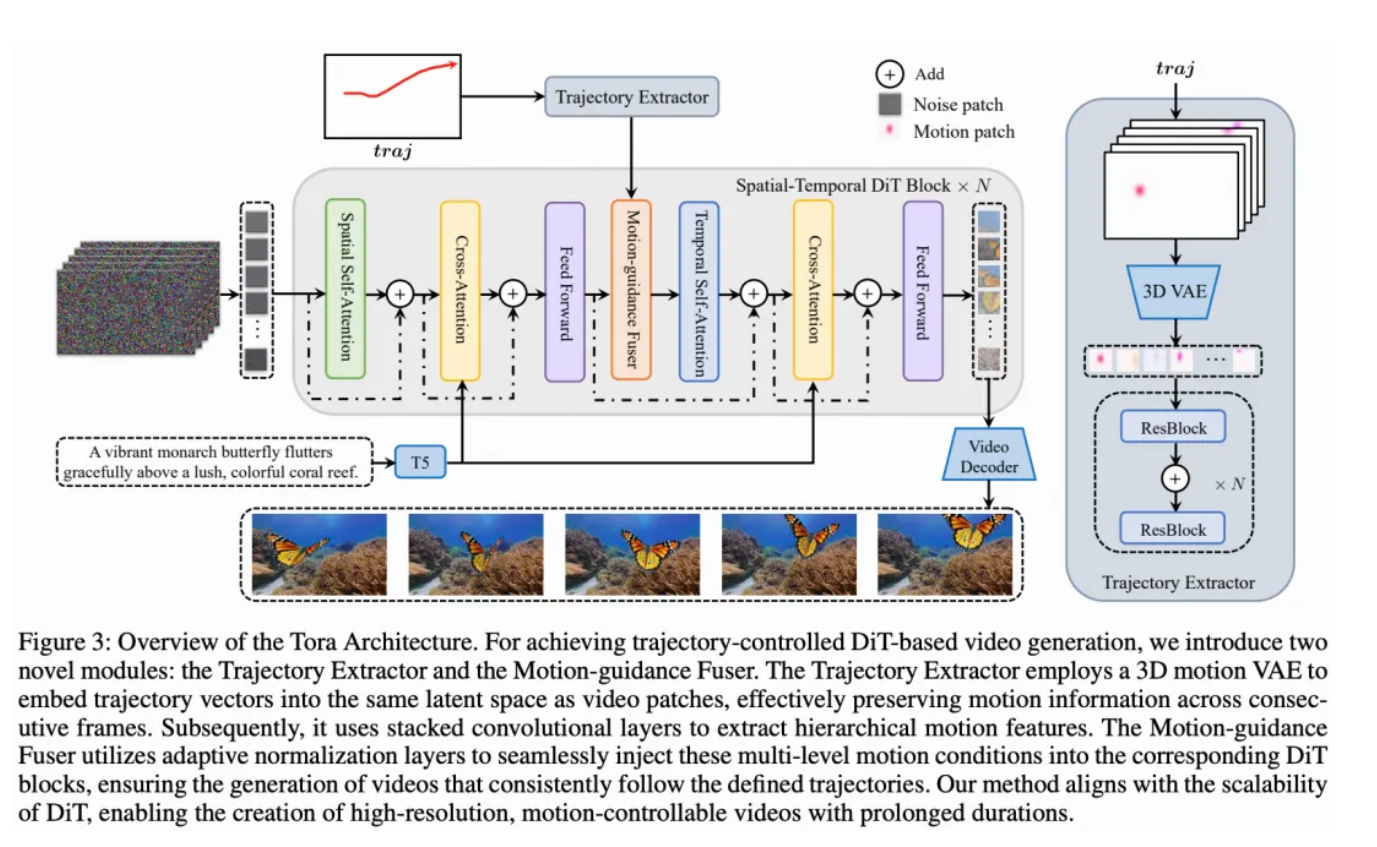
- 架构组成:Tora由轨迹提取器(TE)、时空DiT和运动引导融合器(MGF)组成。TE将轨迹编码为分层时空运动块,MGF将这些运动块整合到DiT块中。
- 训练策略:Tora采用两阶段训练方法进行轨迹学习。第一阶段从训练视频中提取密集光流作为运动轨迹,第二阶段根据运动分段结果和光流分数,从光流中随机选择1到N个对象轨迹样本。
- 性能比较:与先进的运动可控视频生成模型进行定量比较时,Tora在帧数增加时表现出更高的性能优势,保持较高的轨迹控制的稳定度。

Tora的视频生成原理
- 轨迹导向的生成方式:
- Tora是首个轨迹导向的Diffusion Transformer(DiT)框架,它利用轨迹信息来引导视频的生成过程。
- 用户提供的轨迹被编码为多层次时空运动补丁,这些补丁被精细地集成到DiT块中,以确保生成视频的运动与预定义的轨迹一致。
- 整合文本、视觉和轨迹条件:
- Tora不仅依赖轨迹信息,还同时整合文本和视觉条件进行视频生成。
- 这使得Tora能够根据不同的输入条件,生成符合要求的视频内容。
- 利用DiT架构的优势:
- Tora采用DiT作为其基础架构,这是一种开创性的架构创新,结合了扩散模型和transformer架构的优势。
- DiT架构使得Tora能够生成高质量的视频内容,并支持多种时长、纵横比和分辨率。
- 引入新型运动处理模块:
- 为了实现精确且用户友好的运动控制,Tora引入了两个新的运动处理组件:轨迹提取器(Trajectory Extractor, TE)和运动引导融合器(Motion-guidance Fuser, MGF)。
- 轨迹提取器将轨迹编码为分层时空运动块,而运动引导融合器则将这些运动块整合到DiT块中。
- 自适应归一化层的应用:
- Tora通过自适应归一化层将多层次的运动特征引入到相应的DiT块中。
- 这种方法能够确保生成的视频始终遵循预定义的轨迹,同时不影响原有的视觉效果。
Tora的视频生成过程
- 输入条件的处理:
- 用户提供轨迹、文本和/或视觉条件作为输入。
- 轨迹通过轨迹提取器(Trajectory Extractor, TE)被编码为多层次时空运动补丁。
- 轨迹编码:
- TE使用3D视频压缩网络将任意轨迹编码为分层时空运动块,这些运动块与视频块处于相同的潜在空间。
- 轨迹被转换为与视频块相匹配的格式,以便能够精细控制视频内容的动态。
- 时空DiT处理:
- Tora采用时空DiT(Spatial-Temporal DiT)架构,包含空间DiT块和时间DiT块,它们交替排列。
- 这些块通过空间自注意力、时间自注意力和交叉注意力机制处理输入,并利用跳跃连接保持信息的流动性。
- 运动引导融合:
- 运动引导融合器(Motion-guidance Fuser, MGF)将编码后的轨迹(即运动块)整合到每个DiT块中。
- MGF使用了自适应归一化层来动态调整特征,确保视频生成的时间一致性,并维持视频运动的连续性和自然性。
- 视频生成:
- 通过整合文本、视觉和经过编码的轨迹条件,Tora生成遵循轨迹的一致视频。
- 生成的视频可以具有不同的分辨率、纵横比和时长,由ST-DiT架构的可扩展性支持。
- 输出与评估:
- 最终,Tora输出一个遵循预定轨迹的高质量视频。
- 通过对比实验和评估指标(如轨迹精度、视觉质量等)来验证生成视频的效果。
Tora的应用和影响力
- 应用广泛性:Tora支持轨迹、文本、图像三种模态,或它们的组合输入,可对不同时长、宽高比和分辨率的视频内容进行动态精确控制。
- 推动AI视频技术的发展:Tora的推出是阿里巴巴在AI视频生成领域的重要成果,它展示了AI技术在视频生成方面的巨大潜力和应用价值。通过提供更高效、更灵活的视频生成工具,Tora有望推动AI视频技术的进一步发展和普及。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
