Qwen3 Embedding : 阿里通义开源的文本嵌入模型系列
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Qwen3 Embedding 是阿里巴巴通义实验室开源的文本嵌入模型系列,基于 Qwen3 基础模型训练,专为文本表征与检索任务设计。该系列模型支持 119 种语言及编程语言,提供 0.6B、4B、8B 三种参数规模,覆盖轻量级边缘计算到高性能云端场景。Qwen3 Embedding 8B 版本以 70.58 分登顶 MTEB 多语言榜单全球第一,超越众多商业 API 服务,在代码检索、多语言检索等任务中表现卓越。其核心优势在于多语言深度适配、长文本处理能力(32k tokens)及灵活定制化设计,显著降低技术门槛,推动多语言文本处理技术普惠化。
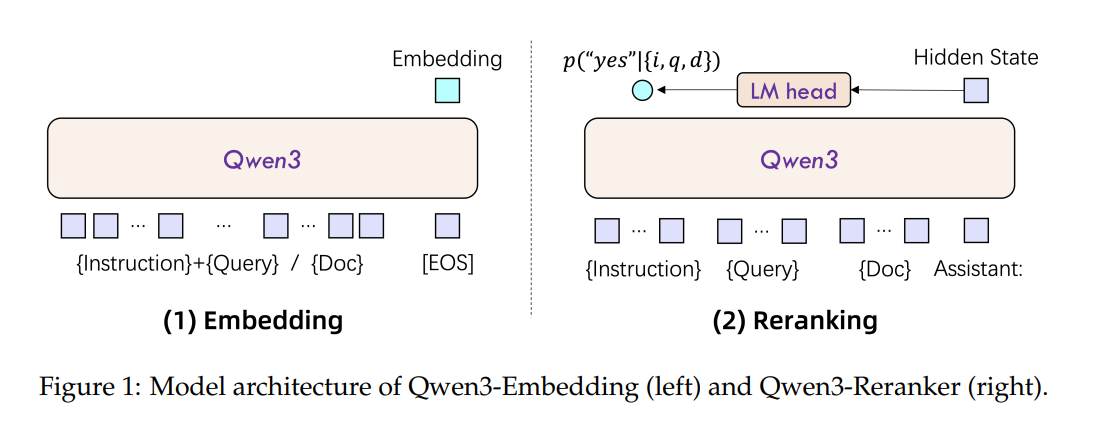
功能特点
- 多语言支持:支持 119 种自然语言及编程语言,涵盖主流语言及 Python、Java 等编程语言。
- 长文本处理:突破性实现 32k tokens 长文本处理能力,集成双块注意力机制,确保长文本语义连贯性。
- 高精度语义表征:通过双编码器架构独立处理查询文本与文档内容,生成高精度语义向量。
- 灵活定制化:支持表征维度自定义及指令适配优化,允许用户根据实际需求调整表征维度,提升特定任务性能。
- 高效部署:以 Apache 2.0 协议开源,支持 Hugging Face、ModelScope 及阿里云 API 一键部署。
优缺点
优点:
- 多语言性能卓越:在多语言检索任务中表现优异,跨语言检索误差率降低 30%。
- 长文本处理能力强:32k tokens 上下文窗口专为法律文书、科研论文等长文档优化。
- 灵活定制化:支持表征维度自定义及指令适配优化,降低应用成本。
- 开源免费:显著降低技术门槛,中小企业可零成本构建文档检索、知识库聚类等系统。
缺点:
- 硬件要求较高:8B 参数模型对硬件资源需求较大,可能限制在资源受限环境下的部署。
- 依赖高质量数据:尽管支持指令适配优化,但性能提升仍需依赖高质量的标注数据。
如何使用
- 通过 Hugging Face 使用:
- 访问 Hugging Face Qwen3 Embedding 页面,选择适合的模型版本(0.6B、4B 或 8B)。
- 使用以下代码加载模型并进行推理:from transformers import AutoTokenizer, AutoModel model_name = “Qwen/Qwen3-Embedding-8B” # 选择适合的模型版本 tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModel.from_pretrained(model_name) text = “This is a sample text.” inputs = tokenizer(text, return_tensors=”pt”, truncation=True, max_length=512) with torch.no_grad(): embeddings = model(**inputs).last_hidden_state[:, 0, :] # 获取 [EOS] 标记的隐藏状态向量
- 通过阿里云 API 使用:
- 访问阿里云官方文档,获取 API 密钥和调用方式。
- 使用 API 调用模型进行文本嵌入生成。
框架技术原理
Qwen3 Embedding 基于 Qwen3 基础模型的密集版本构建,采用三阶段训练框架:
- 大规模无监督预训练:利用 Qwen3 指令模型合成大规模、高质量、多语言和多任务的文本相关性数据集,进行初始的无监督训练。
- 监督微调:从合成数据中筛选出高质量的小规模数据,使用基于 InfoNCE 框架的改进对比损失函数进行优化。
- 模型融合:使用球面线性插值(slerp)技术,将监督微调过程中保存的多个模型检查点合并,提升模型在不同数据分布上的鲁棒性和泛化性能。
创新点
- 多阶段训练流程:通过大规模弱监督预训练、监督微调及模型融合策略,显著提升模型性能。
- 双编码器架构:独立处理查询文本与文档内容,生成高精度语义向量。
- 长文本处理机制:集成双块注意力机制,有效避免长程信息丢失,确保 32k 上下文内语义连贯性。
- 灵活定制化设计:支持表征维度自定义及指令适配优化,满足不同场景需求。
评估标准
- MTEB 多语言榜单:Qwen3 Embedding 8B 版本以 70.58 分登顶全球第一,超越众多商业 API 服务。
- 代码检索任务:在 MTEB-Code 任务中,搜索精准度排名第一。
- 多语言检索任务:在多模态文本嵌入(MTEB)跨语言场景下,取得 69.02 的高分。
- 中文检索任务:得分达到 77.45,显著优于传统 BM25 和 ColBERT 等基线模型。
- 英文检索任务:得分达到 69.76,表现优异。
应用领域
- 语义搜索:用于构建高效、精准的语义搜索引擎。
- 问答系统:为问答系统提供高质量的文本嵌入,提升回答准确性。
- 推荐系统:通过文本嵌入实现更精准的内容推荐。
- 文档检索:支持法律文书、科研论文等长文档的检索与聚类。
- 知识库构建:助力企业构建高效、易用的知识库系统。
项目地址
- Hugging Face:Qwen3 Embedding 集合
- GitHub:Qwen3-Embedding 仓库
- ModelScope:Qwen3 Embedding 集合
- 技术报告:Qwen3 Embedding 技术报告
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
