Self Forcing : Adobe联合德克萨斯大学推出的视频生成模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Self Forcing 是 Adobe Research 与德克萨斯大学奥斯汀分校联合推出的一种新型自回归视频生成算法,旨在解决传统生成模型在训练与测试时存在的暴露偏差问题。通过在训练阶段模拟自生成过程,以先前生成的帧为条件生成后续帧,而非依赖真实帧,Self Forcing 成功弥合了训练与测试分布的差异,显著提升了生成视频的质量和稳定性。该模型支持理论上无限长的视频生成,在单个 H100 GPU 上可实现 17 FPS 的实时生成能力,延迟低于一秒,为直播、游戏和实时交互应用提供了新的可能性。
功能特点
- 高效实时视频生成:在单个 GPU 上实现 17 FPS 的实时生成能力,延迟低于一秒,适合实时应用场景。
- 无限长视频生成:通过滚动 KV 缓存机制,支持理论上无限长的视频生成,不会因长度限制而中断。
- 高质量生成:生成的视频质量与当前最先进的扩散模型相媲美,甚至更优,动作自然,无过饱和伪影。
- 低资源需求:能在单张 RTX 4090 显卡上实现流式视频生成,降低了对硬件资源的依赖。
- 多模态支持:支持文生视频和结合 VACE 图生视频,满足不同创作需求。
优缺点
优点:
- 实时性高:生成速度快,延迟低,适合实时应用场景。
- 生成质量好:生成的视频质量高,动作自然,无过饱和伪影。
- 资源需求低:能在普通设备上部署和使用,降低了硬件门槛。
- 无限长生成:支持理论上无限长的视频生成,为动态视频创作提供了强大的支持。
缺点:
- 计算复杂度:尽管采用了少步扩散模型和梯度截断策略,但自回归生成过程仍可能带来较高的计算复杂度。
- 模型优化:对于特定场景或需求,可能需要进行进一步的模型优化和调整。
如何使用
- 访问项目地址:获取模型的代码和预训练权重。
- 环境配置:按照项目文档配置开发环境,包括安装必要的依赖库和框架。
- 模型加载:加载预训练模型或根据需求进行微调。
- 输入指令:通过文本、图像或视频片段等方式输入生成指令。
- 生成视频:运行模型生成视频,并根据需要进行后处理和优化。
此外,还可以使用线上平台如 RunningHub 来运行体验,降低本地算力要求。
框架技术原理
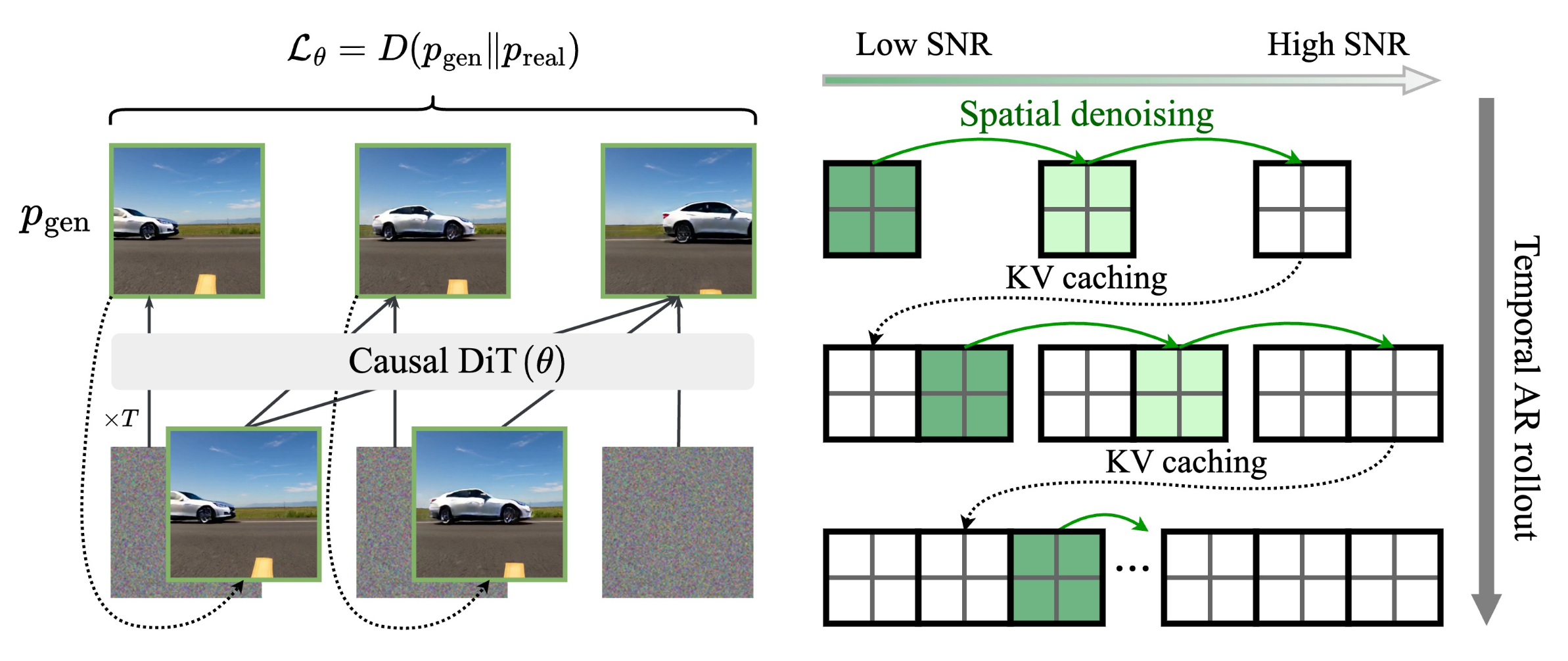
Self Forcing 的核心思想是在训练阶段模拟推理时的自回归生成过程,即每一帧的生成都基于模型自身之前生成的帧,而非真实帧。通过视频级别的整体分布匹配损失函数对整个生成序列进行监督,模型能直接从自身预测的错误中学习,有效减轻暴露偏差。同时,引入滚动 KV 缓存机制,维护一个固定大小的缓存区,存储最近几帧的 KV 嵌入,以支持长视频生成。此外,还采用了少步扩散模型和梯度截断策略,提高训练效率。
创新点
- 自回归生成模拟:在训练阶段模拟推理时的自回归生成过程,弥合训练与测试分布的差异。
- 滚动 KV 缓存机制:支持理论上无限长的视频生成,提高了生成效率。
- 少步扩散模型与梯度截断策略:降低了计算复杂度,提高了训练效率。
- 整体分布匹配损失函数:对整个生成序列进行监督,提高了生成视频的质量和稳定性。
评估标准
- 生成质量:评估生成视频的视觉质量、动作自然度、无过饱和伪影等。
- 生成速度:评估模型的生成速度,包括帧率和延迟。
- 资源需求:评估模型对硬件资源的依赖程度,包括显存占用和内存占用。
- 多样性:评估模型生成的视频是否具有多样性,能否满足不同创作需求。
应用领域
- 直播与实时视频流:实时生成虚拟背景、特效或动态场景,为观众带来全新的视觉体验。
- 游戏开发:实时生成游戏场景和特效,增强游戏的沉浸感和交互性。
- 虚拟现实与增强现实:为 VR 和 AR 应用提供实时的视觉内容,如实时生成逼真的虚拟场景或叠加虚拟元素。
- 内容创作与视频编辑:帮助创作者快速生成高质量的视频内容,提高创作效率。
项目地址
- 项目官网:https://self-forcing.github.io/
- GitHub仓库:https://github.com/guandeh17/Self-Forcing
- arXiv技术论文:https://arxiv.org/pdf/2506.08009
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
