Skywork-SWE-32B : 昆仑万维开源的自主代码智能体基座模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
Skywork-SWE-32B 是昆仑万维于 2025 年 6 月 20 日开源的自主代码智能体基座模型,专注于软件工程(SWE)任务。该模型在 32B 参数规模下实现了业界领先的仓库级代码修复能力,通过构建超过 1 万个可验证的 GitHub 仓库任务实例,打造出目前最大规模的可验证 GitHub 仓库级代码修复数据集,并系统性验证了大模型在软件工程任务上的数据缩放定律(Scaling Law)。Skywork-SWE-32B 在 SWE-bench Verified 基准测试中以 38.0% 的 pass@1 准确率创下开源模型纪录,应用测试时扩展技术后更提升至 47.0%,性能超越多数主流闭源模型,标志着开源代码智能体技术迈入新阶段。
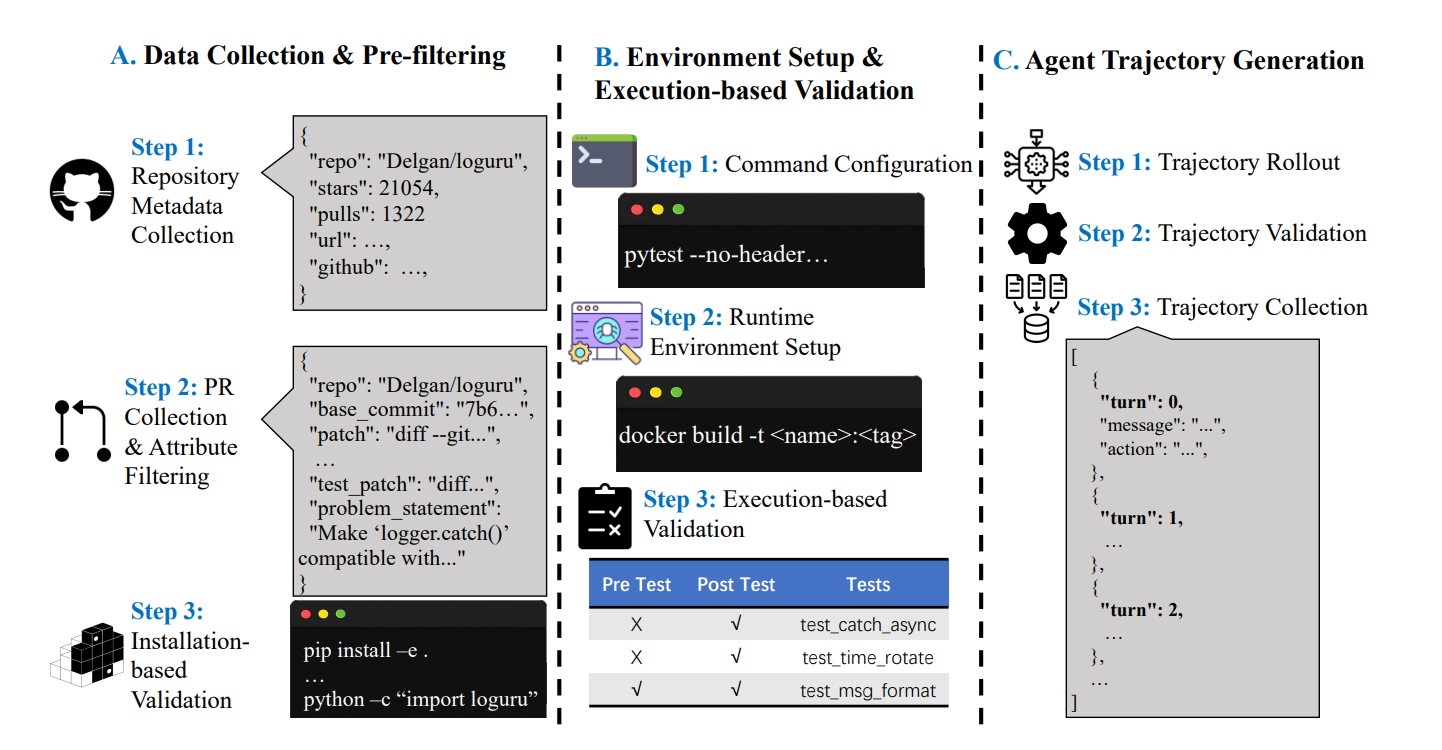
功能特点
- 仓库级代码修复:能够定位并修复 GitHub 仓库中的实际代码问题,涵盖从 BUG 定位到修复效果验证的完整闭环。
- 多轮交互与长上下文处理:支持超多轮交互和超长上下文推理,能够处理复杂的代码修复任务。
- 跨文件依赖与工具链调用:具备处理跨文件依赖和调用工具链的能力,能够在复杂环境中持续修复代码问题。
- 高质量数据集支持:基于 Skywork-SWE 数据集训练,该数据集包含超过 1 万条高质量任务实例,覆盖主流开源项目及中小型代码库。
优缺点
优点:
- 性能卓越:在 SWE-bench Verified 基准测试中取得优异成绩,超越多数开源和闭源模型。
- 数据驱动:通过构建大规模、高质量的可验证数据集,系统性验证了数据缩放定律在软件工程任务中的有效性。
- 开源友好:模型权重、技术报告及数据集全面开放,便于社区进行二次开发和优化。
缺点:
- 计算资源需求:尽管模型参数规模为 32B,但训练和推理仍需要较高的计算资源。
- 多语言支持有限:目前主要支持英文代码仓库,多语言支持需进一步拓展。
如何使用
- 访问项目地址:从 HuggingFace 模型库获取模型权重和技术报告。
- 环境配置:安装必要的依赖库和框架,如 PyTorch、Transformers 等。
- 模型加载:加载预训练模型或根据需求进行微调。
- 输入指令:通过文本或代码片段输入修复指令,模型将生成修复后的代码。
- 验证与优化:使用单元测试验证修复效果,并根据需要进行后处理和优化。
框架技术原理
Skywork-SWE-32B 基于开源 OpenHands 代码 Agent 框架,通过微调 Skywork-SWE 数据集的高质量智能体轨迹得到。其技术原理包括:
- 数据收集与验证:构建自动化、结构化、可复现的 SWE 数据收集与验证流程,确保数据质量。
- 模型训练:利用大规模、高质量的可验证数据集进行模型训练,系统性验证数据缩放定律。
- 测试时扩展技术:引入测试时扩展技术(TTS),进一步提升模型性能。
创新点
- 仓库级代码修复能力:在开源 32B 模型规模下实现了业界最强的仓库级代码修复能力。
- 大规模可验证数据集:构建了超过 1 万个可验证的 GitHub 仓库任务实例,为模型训练提供坚实基础。
- 数据缩放定律验证:系统性验证了大模型在软件工程任务上的数据缩放定律,为后续模型发展提供理论基础。
- 开源策略:坚定开源策略,助力社区在大语言模型驱动的软件工程研究中持续演进。
评估标准
- 代码修复准确率:在 SWE-bench Verified 基准测试中评估模型的 pass@1 准确率。
- 性能对比:与同等参数规模的开源模型及参数量更大的闭源模型进行性能对比。
- 数据集质量:评估数据集的规模、质量和多样性,确保模型训练的有效性。
- 工程实用性:评估模型在实际软件开发场景中的表现,如修复效率、代码质量等。
应用领域
- 软件开发:辅助开发者进行代码修复、优化和测试,提高开发效率和代码质量。
- 代码教育:作为教学工具,帮助学生理解代码问题的解决过程,提高编程能力。
- 代码研究:为研究人员提供实验平台,用于探索大语言模型在软件工程任务中的应用。
- 企业开发:集成到企业内部开发工具中,自动化处理代码问题,减少人工干预。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
