OmniAvatar:浙大联合阿里推出的音频驱动全身视频生成模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
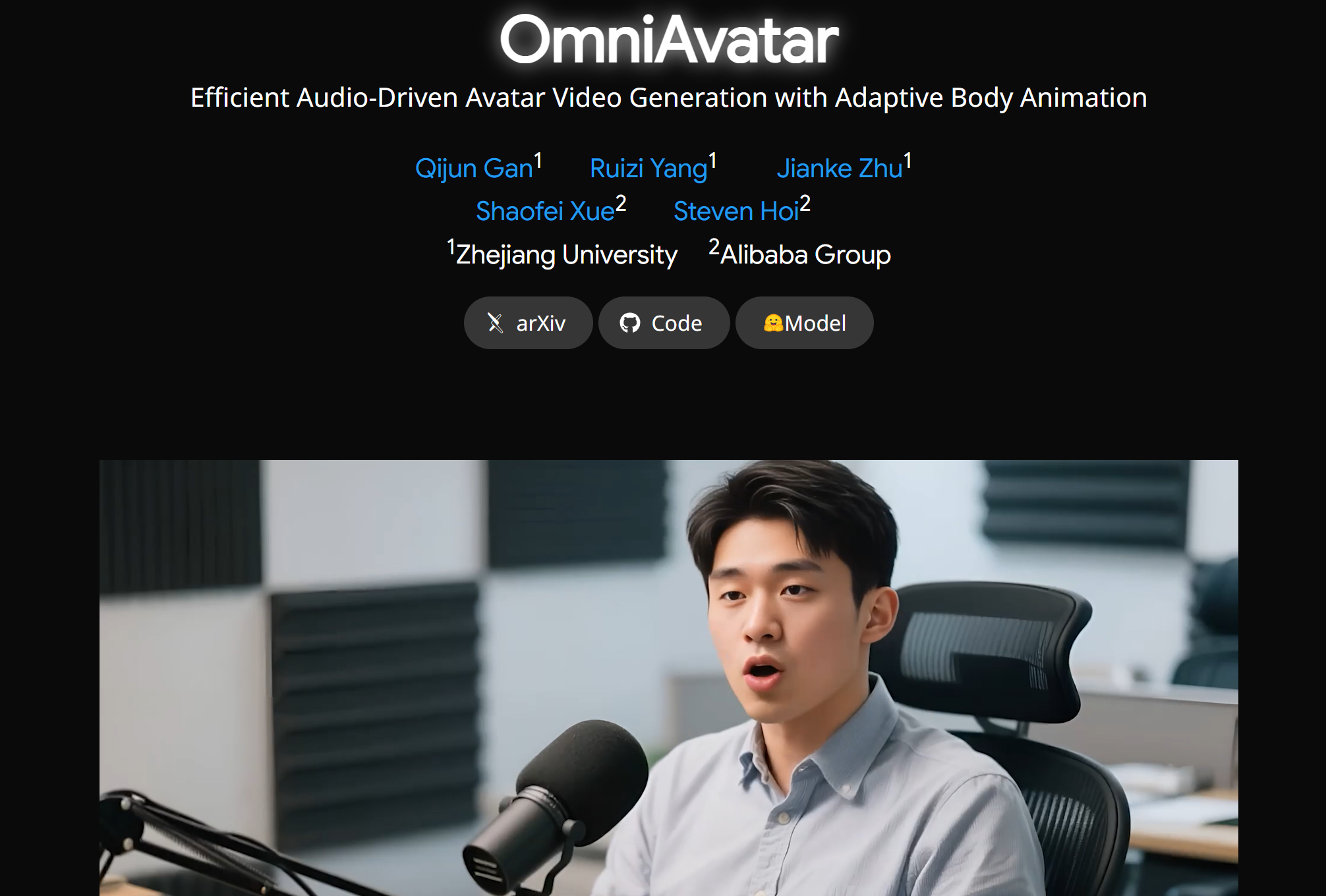
OmniAvatar是浙江大学与阿里巴巴联合推出的音频驱动全身视频生成模型,旨在通过音频输入生成具备自然全身动作的虚拟人视频。该模型通过引入逐像素多层次音频嵌入策略和基于LoRA的训练方法,有效解决了唇动同步与真实动态身体动作生成的核心挑战,实现了面部及半身视频生成方面的显著突破,并能够基于文本提示实现精确控制。
功能特点
- 全身动作生成:OmniAvatar能够生成具备自适应且自然全身动作的说话虚拟人视频,而不仅仅是面部动作。
- 高精度唇型同步:通过逐像素多层次音频嵌入策略,确保唇动与音频的高度同步。
- 基于文本提示的控制:支持通过文本提示实现精确控制,如指定角色的情绪、动作等。
- 支持手势控制和背景调整:用户可以根据需要调整虚拟人的手势和背景,增强视频的交互性和真实感。
优缺点
优点:
- 自然流畅的动作表现:OmniAvatar在生成人物头像的自然性与表现力方面表现出色,动作流畅自然。
- 高精度控制:通过文本提示和LoRA训练方法,实现了对虚拟人动作和表情的精确控制。
- 广泛的应用场景:适用于播客、人际互动、动态场景和歌唱等多种视频生成领域。
缺点:
- 颜色偏移问题:模型继承了基础模型的缺陷,如颜色偏移,可能导致生成的视频在色彩上与真实场景存在差异。
- 长视频误差累积:在长视频生成中,由于误差累积,可能导致视频质量下降。
- 复杂文本控制局限:尽管支持文本提示控制,但在复杂文本控制方面仍难以区分发言角色或多角色交互。
- 推理时间长:扩散推理需多次去噪,推理时间长,难以满足实时交互需求。
如何使用
OmniAvatar的具体使用方式可能因模型版本和部署环境而异。一般来说,用户可以通过以下步骤使用该模型:
- 准备输入数据:包括音频文件、文本提示(如需要)以及可能的参考图像。
- 选择部署环境:根据需求选择本地部署或云端部署。
- 调用模型API:通过调用OmniAvatar的API接口,将输入数据传递给模型进行处理。
- 获取生成结果:模型处理完成后,用户可以获取生成的虚拟人视频。
框架技术原理
- 多层次音频嵌入策略:为了多层次捕捉音频特征,OmniAvatar提出了多层级音频嵌入策略,以保持音频与视频之间的逐像素对齐。
- 基于LoRA的训练方法:在DiT模型的各层中引入了基于LoRA的训练方法,以在引入音频作为新条件的同时保留基础模型的强大能力。
- 帧重叠机制与参考图像嵌入策略:为了在长视频生成中保持一致性与时间连续性,引入了帧重叠机制与参考图像嵌入策略。
创新点
- 逐像素多层次音频嵌入:通过逐像素多层次音频嵌入策略,实现了音频与视频之间的精细对齐,提高了唇动同步精度。
- 基于LoRA的训练方法:引入了基于LoRA的训练方法,有效保留了基础模型的强大能力,同时实现了对音频条件的灵活引入。
- 全身动作生成能力:与传统的仅生成面部动作的模型相比,OmniAvatar能够生成具备自然全身动作的虚拟人视频,增强了视频的真实感和交互性。
评估标准
- 唇动同步精度:评估生成的虚拟人视频中唇动与音频的同步程度。
- 动作自然性:评估生成的虚拟人动作是否自然流畅,是否符合人体运动规律。
- 文本控制精度:评估模型对文本提示的响应程度和控制精度。
- 视频质量:评估生成的视频在色彩、分辨率、清晰度等方面的质量。
应用领域
- 播客与视频制作:OmniAvatar可用于生成高质量的播客和视频内容,降低制作成本和时间。
- 人际互动与虚拟助手:通过生成具备自然全身动作的虚拟人视频,增强人际互动和虚拟助手的真实感和交互性。
- 动态场景与歌唱:适用于需要动态场景和歌唱表演的视频生成领域,如音乐视频、舞台表演等。
项目地址
- 项目官网:https://omni-avatar.github.io/
- GitHub仓库:https://github.com/Omni-Avatar/OmniAvatar
- HuggingFace模型库:https://huggingface.co/OmniAvatar/OmniAvatar-14B
- arXiv技术论文:https://arxiv.org/pdf/2506.18866
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
