10月12日·谷歌 ReasoningBank 让 AI 从成功与失败中双向学习
10月12日·周日 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
谷歌 ReasoningBank 让 AI 从成功与失败中双向学习
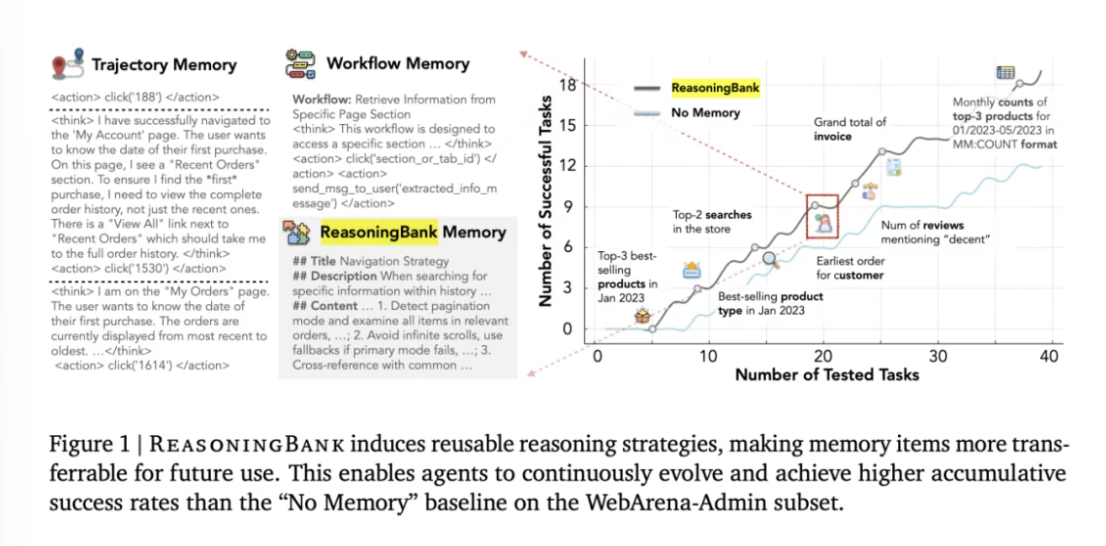
谷歌在最新研究中提出了 ReasoningBank,一种创新的记忆框架,用于智能体系统的自我进化。该框架无需真实标签,通过提炼智能体的成功经验和失败教训,形成结构化的记忆项,指导智能体在新任务中的决策。ReasoningBank 与记忆感知的测试时扩展(MaTTS)相结合,在网页浏览、软件工程等任务中表现出色,显著提升了智能体的有效性和效率。谷歌通过并行扩展和顺序扩展两种方式,进一步优化了记忆的策划和利用,实现了记忆与测试时扩展之间的协同效应,推动了 AI 的自我进化范式。来源:微信公众号【机器之心】
Qwen3 转化为扩散语言模型 RND1-Base 创 30B 参数纪录
Radical Numerics 团队在自回归模型 Qwen3 的基础上,成功转化出 30B 参数的扩散语言模型 RND1-Base。该模型通过简单持续预训练(SCP)方法,从自回归模型中继承了强大的语言知识,并在大规模预训练中实现了完整的扩散行为。RND1-Base 在多项基准测试中超越了现有模型,展示了其卓越的性能和泛化能力。该研究不仅证明了自回归到扩散模型的高效转换方法,还为扩散语言模型的规模化训练提供了新的思路。来源:微信公众号【机器之心】

清华大学研究揭示强化学习提升 VLA 泛化性的独特优势
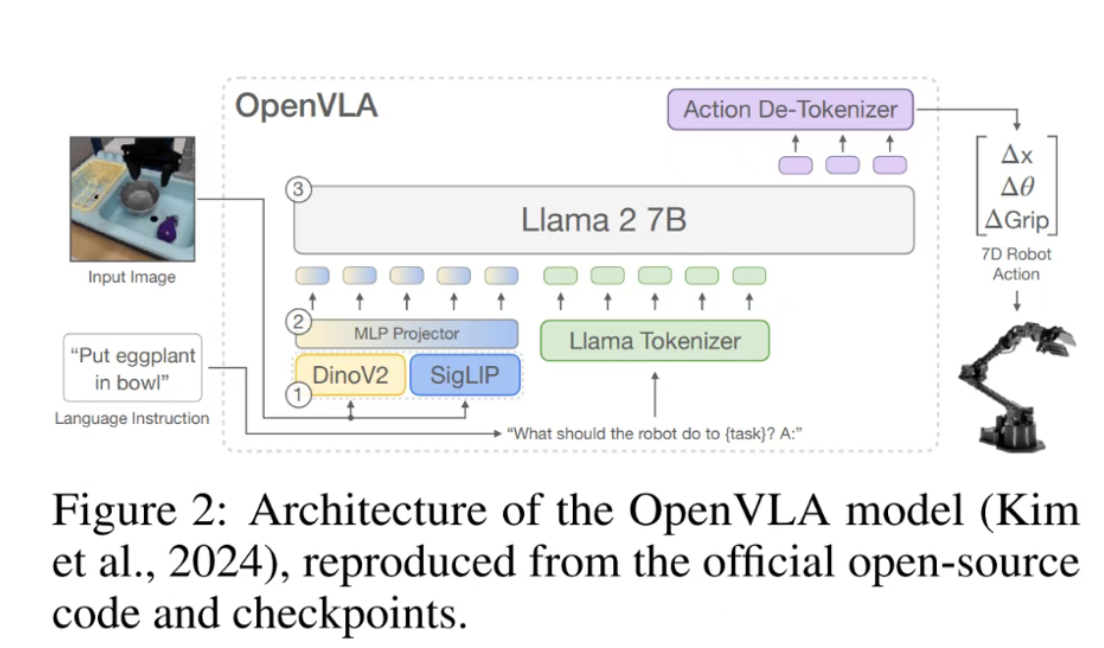
清华大学团队在 NeurIPS 2025 发表文章,首次系统性地分析了强化学习(RL)在提升视觉 – 语言 – 动作(VLA)大模型泛化能力上的独特优势。研究发现,PPO 算法在机器人控制任务中显著提升了模型的鲁棒性和泛化性,特别是在语义理解和任务执行上表现出色。团队提出了高效 PPO 训练方案,包括共享 Actor-Critic 架构设计、模型预热策略和最小化训练轮次,大幅提升了训练效率。实验表明,RL 在分布外任务上相比有监督微调(SFT)具有更强的泛化能力。来源:微信公众号【量子位】
AI 知识助手 remio 打造用户专属的“第二大脑”
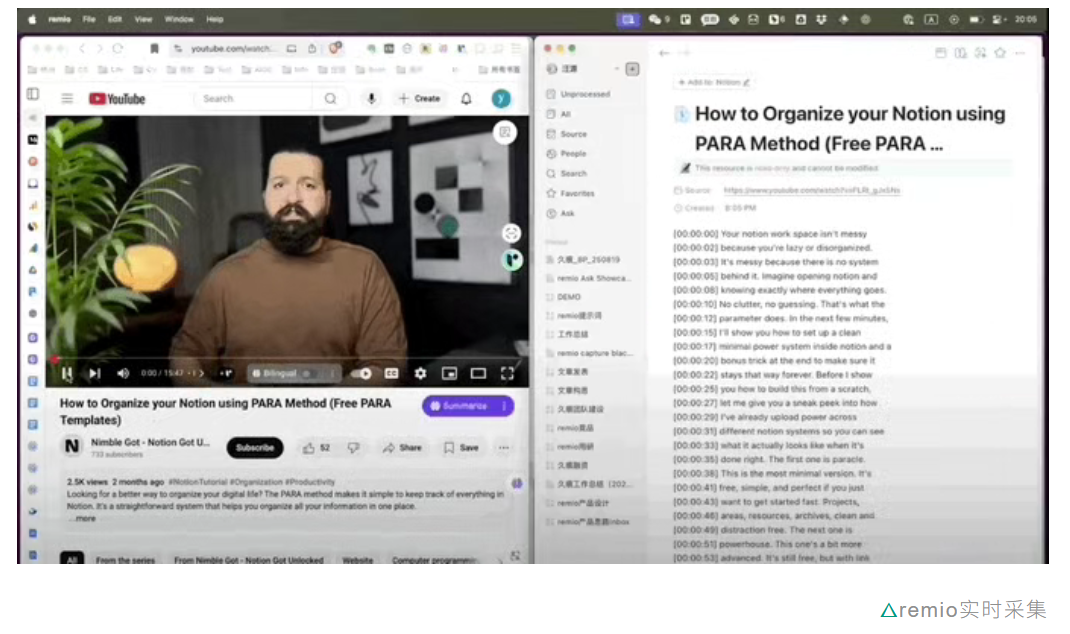
AI 知识助手 remio 通过无感自动化信息采集,致力于成为用户记忆和信息管理的“第二大脑”。remio 能实时采集网页、文档、视频等信息,自动分类并保存到本地知识库,支持自然语言提问和 AI 辅助创作。其核心功能包括自动信息捕获、智能知识管理、隐私保护等。remio 通过本地化优化和深度适配,实现了高效的信息采集和处理,为用户提供个性化的知识管理体验。其目标用户是复杂知识工作者,未来将覆盖更多办公数据类型和平台,进一步提升工作效率。来源:微信公众号【量子位】
抖音 & LV – NUS 开源多模态模型 SAIL – VL2 刷新 SOTA
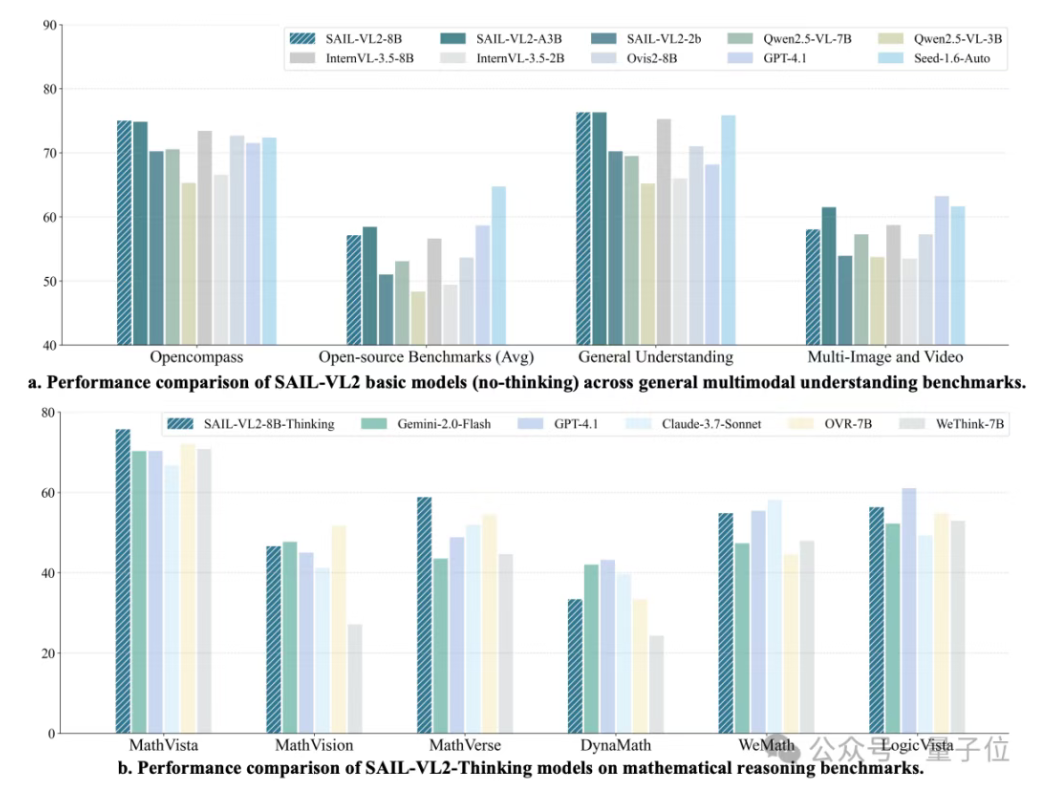
抖音 SAIL 团队与 LV – NUS Lab 联合推出的多模态大模型 SAIL – VL2,在 106 个数据集上实现性能突破,尤其在复杂推理任务中表现出色。SAIL – VL2 通过架构创新(稀疏 MoE + 灵活编码器)、数据优化(评分过滤 + 合成增强)和训练策略(渐进式框架 + 动态学习率)三大维度的改进,实现了小模型的强能力。其后训练策略包括五阶段递进强化能力,进一步提升了模型的综合性能。SAIL – VL2 提供了开源模型和推理代码,为社区提供了一个可扩展的多模态基础模型。来源:微信公众号【量子位】
相关文章
