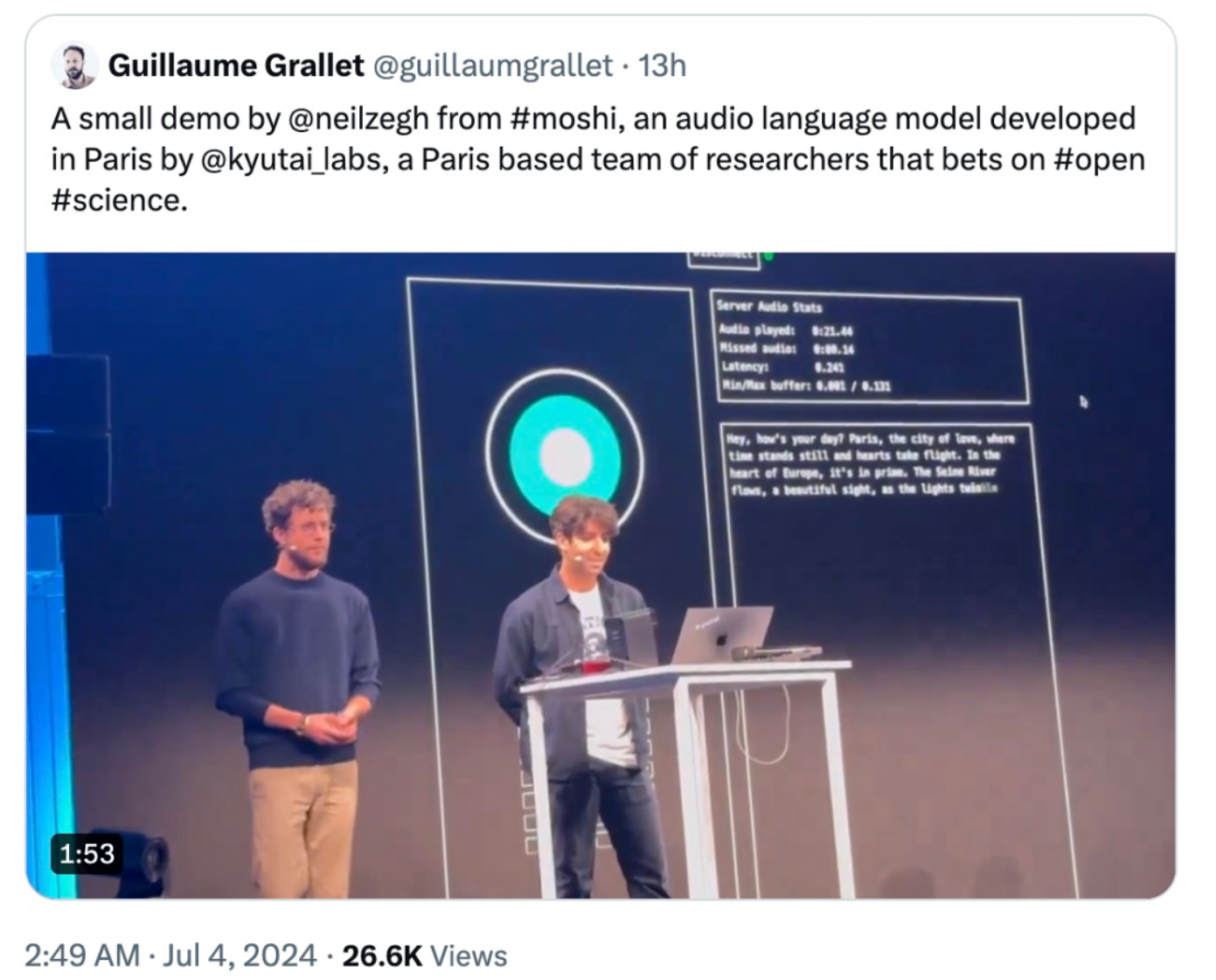
Moshi——法国AI实验室Kyutai开发的一款实时音频多模态模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Moshi介绍
Moshi是法国AI实验室Kyutai开发的一款实时音频多模态模型,该模型旨在通过结合音频、文本和视觉等多模态信息,实现更加自然和丰富的交互体验。Moshi利用先进的深度学习技术,能够从多个维度理解和生成音频内容,为语音交互、语音合成、音频分析等领域提供了新的可能性。
Moshi功能特点
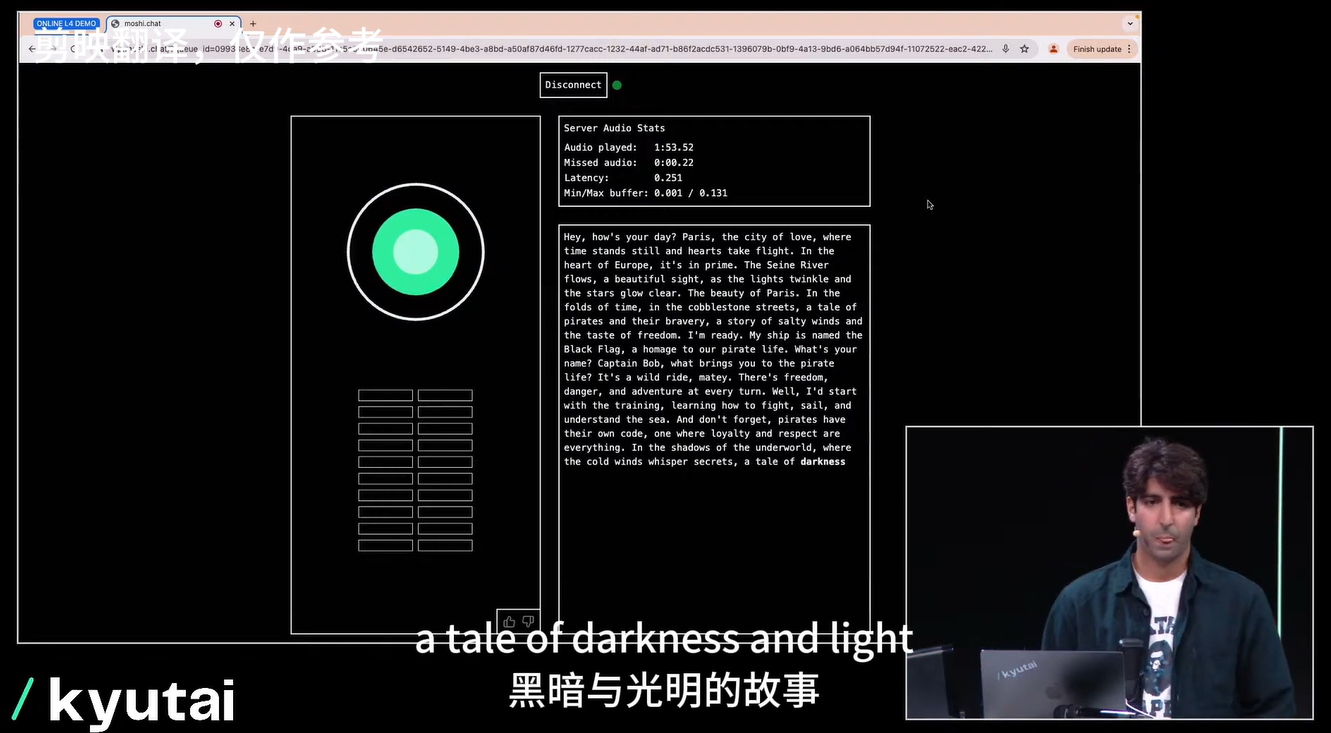
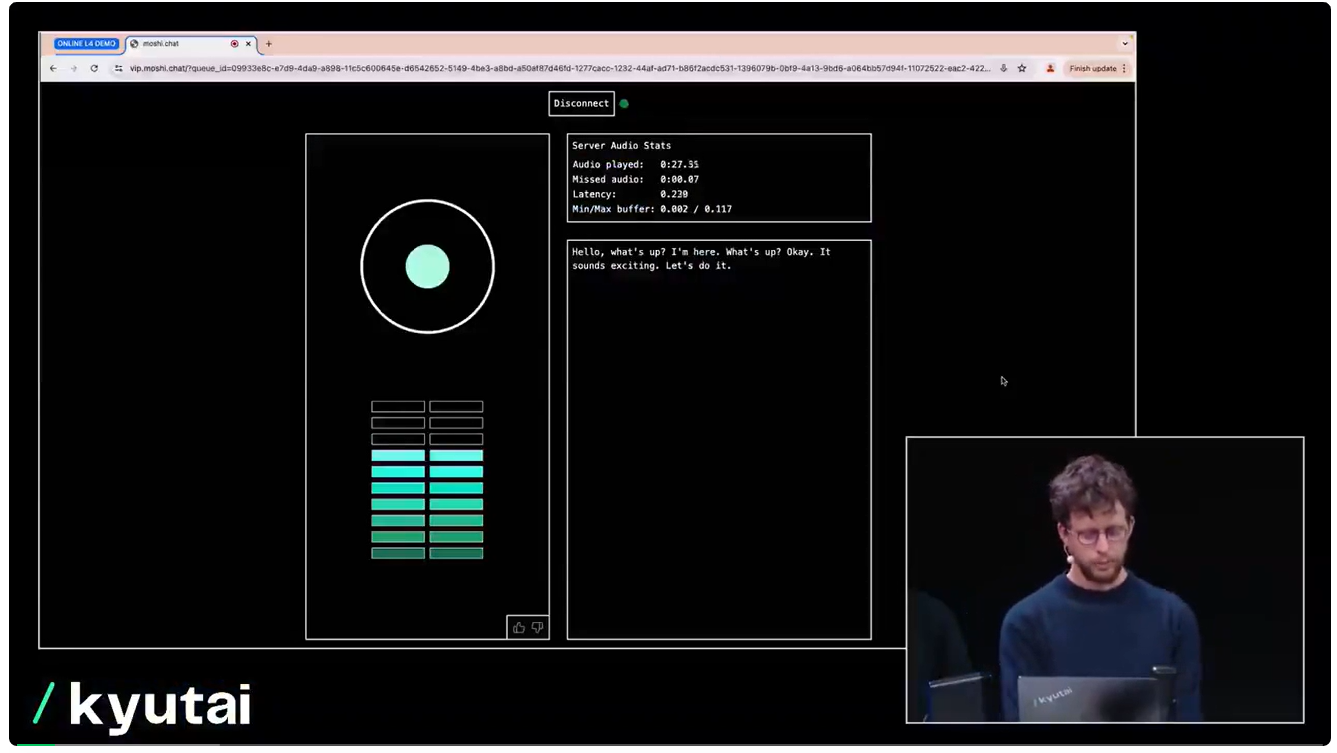
- 实时音频处理:Moshi能够实时处理输入的音频信号,提取其中的关键信息并进行相应的处理和分析。
- 多模态融合:该模型能够将音频、文本和视觉等多种模态的信息进行融合,提高信息的丰富度和准确性。
- 灵活的应用场景:Moshi可应用于语音助手、自动字幕生成、语音识别与合成等多个领域,满足不同场景下的需求。
Moshi的优缺点
- 优点:
- 实时处理能力强,能够快速响应输入并生成结果。
- 多模态融合提高了信息的丰富度和准确性。
- 灵活的应用场景,适用于多种不同的需求。
- 缺点:
- 对计算资源要求较高,可能需要在高性能硬件上运行。
- 在处理复杂场景或多语种输入时,可能存在一定的挑战。
Moshi的主要应用场景
- 语音助手:提供更加自然和智能的语音交互体验。
- 自动字幕生成:根据音频内容自动生成准确的字幕。
- 语音识别与合成:实现高精度的语音识别和流畅的语音合成。
如何使用Moshi
使用Moshi通常需要具备一定的技术背景,包括深度学习、音频处理等相关知识。用户可以通过下载Kyutai实验室提供的Moshi模型、准备相应的音频和文本数据、配置相关参数等步骤来实现Moshi的应用。具体使用方法可参考官方文档或教程。
Moshi的训练方法
Moshi的训练方法主要涉及多模态数据的收集和标注、模型架构的设计和优化、训练算法的选择和调整等步骤。通过大规模多模态数据的训练,Moshi能够学习到音频、文本和视觉等不同模态之间的关联和映射关系,从而提高其多模态融合和处理能力。
Moshi的框架结构
Moshi的框架结构通常包括音频处理模块、文本处理模块、视觉处理模块以及多模态融合模块等组成部分。这些模块协同工作,共同实现音频的多模态处理和分析。
Moshi的创新点
- 实时音频多模态处理:Moshi能够在实时处理音频信号的同时,结合文本和视觉等多模态信息,提高信息的丰富度和准确性。
- 灵活的应用场景:Moshi可应用于多种不同的场景和需求,具有较强的通用性和灵活性。
Moshi的评估标准
评估Moshi的性能通常包括实时处理速度、多模态融合效果、语音识别准确率、语音合成质量等多个方面。这些标准旨在全面评价Moshi在实时音频多模态处理方面的表现和性能水平。
Moshi的影响
Moshi的推出对音频处理和多模态交互领域产生了积极的影响。它推动了实时音频多模态处理技术的发展和应用,为语音助手、自动字幕生成、语音识别与合成等领域提供了新的解决方案和可能性。同时,Moshi也促进了多模态交互技术的研究和发展,为相关领域的研究者和开发者提供了宝贵的参考和启示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
