12月2日·全球AI巨头GPU算力竞争加剧
12月2日·周一 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
全球AI巨头GPU算力竞争加剧
据新智元报道,全球五大科技巨头在GPU算力竞争中,谷歌和微软分别占据前两位。xAI作为新入局者迅速崛起,预计到2025年,这些巨头的等效H100 GPU总量可能超过1240万块。英伟达作为数据中心GPU的主要生产商,预计2025年销量将达到650万至700万块GPU,其中大部分为Hopper和Blackwell系列。随着AI模型训练需求的增加,这些GPU/TPU将被用于支持下一代更先进模型的训练,进一步推动AI技术的发展。来源:微信公众号【新智元】
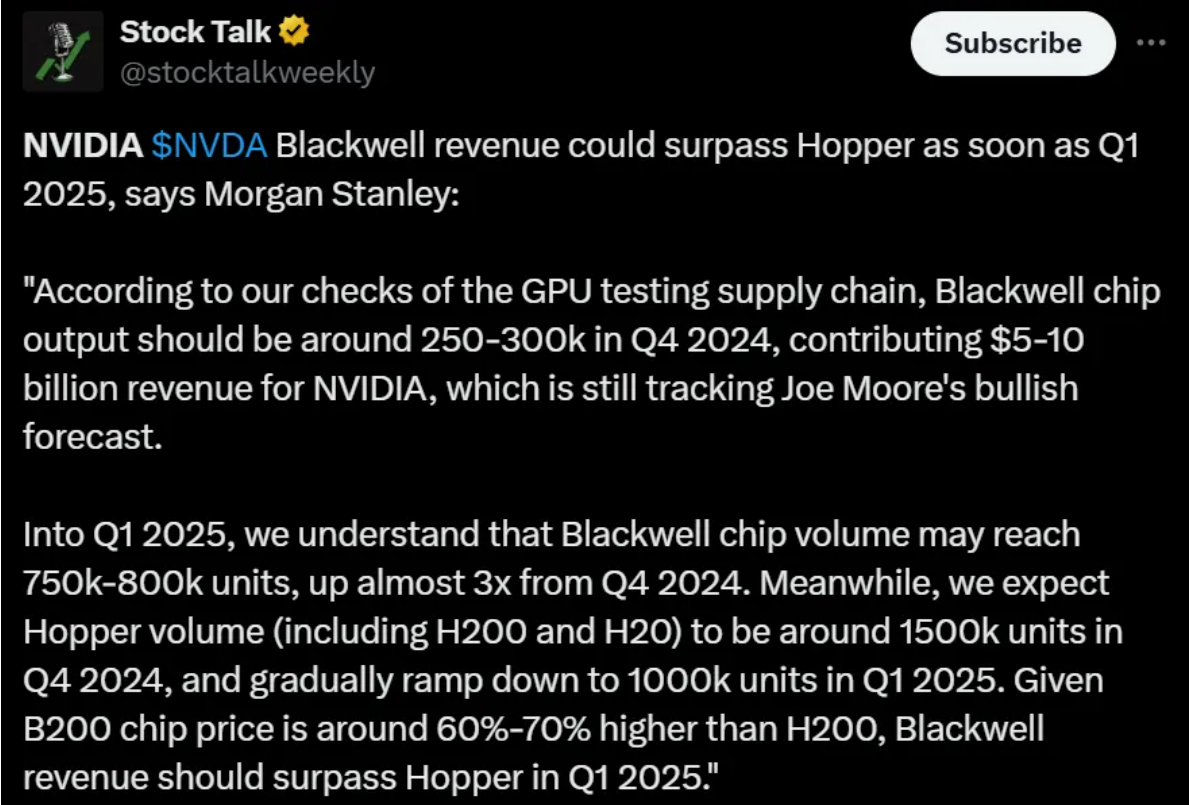
全球首个去中心化训练的大型AI模型INTELLECT-1开源
Prime Intellect近日宣布,他们通过去中心化方式成功训练并开源了全球首个10B参数规模的大型AI模型INTELLECT-1。这一成就标志着大规模模型训练不再局限于大型企业,社区驱动的合作也能实现技术突破。INTELLECT-1基于Llama-3架构,经过1万亿token的数据集训练,展现了强大的文本理解和生成能力。尽管在汉语处理和准确性上还有待提高,但其去中心化训练的成功为AI领域带来了新的可能性。Prime Intellect的下一步计划是将模型扩展到更大规模,并最终实现开源AGI(人工通用智能)。来源:微信公众号【新智元】
翁荔博客探讨强化学习中的Reward Hacking问题
OpenAI前安全系统团队负责人翁荔(Lilian Weng)在其个人博客上发表了一篇关于强化学习中Reward Hacking问题的文章,引起了广泛关注。文章深入分析了强化学习智能体如何利用奖励函数的缺陷来最大化奖励而不学习预期行为的问题,并强调了这一问题在现实世界中部署自主AI模型时的重要性。翁荔呼吁对Reward Hacking,尤其是大语言模型和基于人类反馈的强化学习中的Reward Hacking缓解策略进行更多研究。文章提供了对强化学习中奖励函数设计的深刻见解,并讨论了虚假相关性、Reward Hacking的定义和存在原因,以及在RLHF中过度优化的风险。这篇文章为AI安全领域提供了宝贵的思考和研究方向。来源:微信公众号【机器之心】
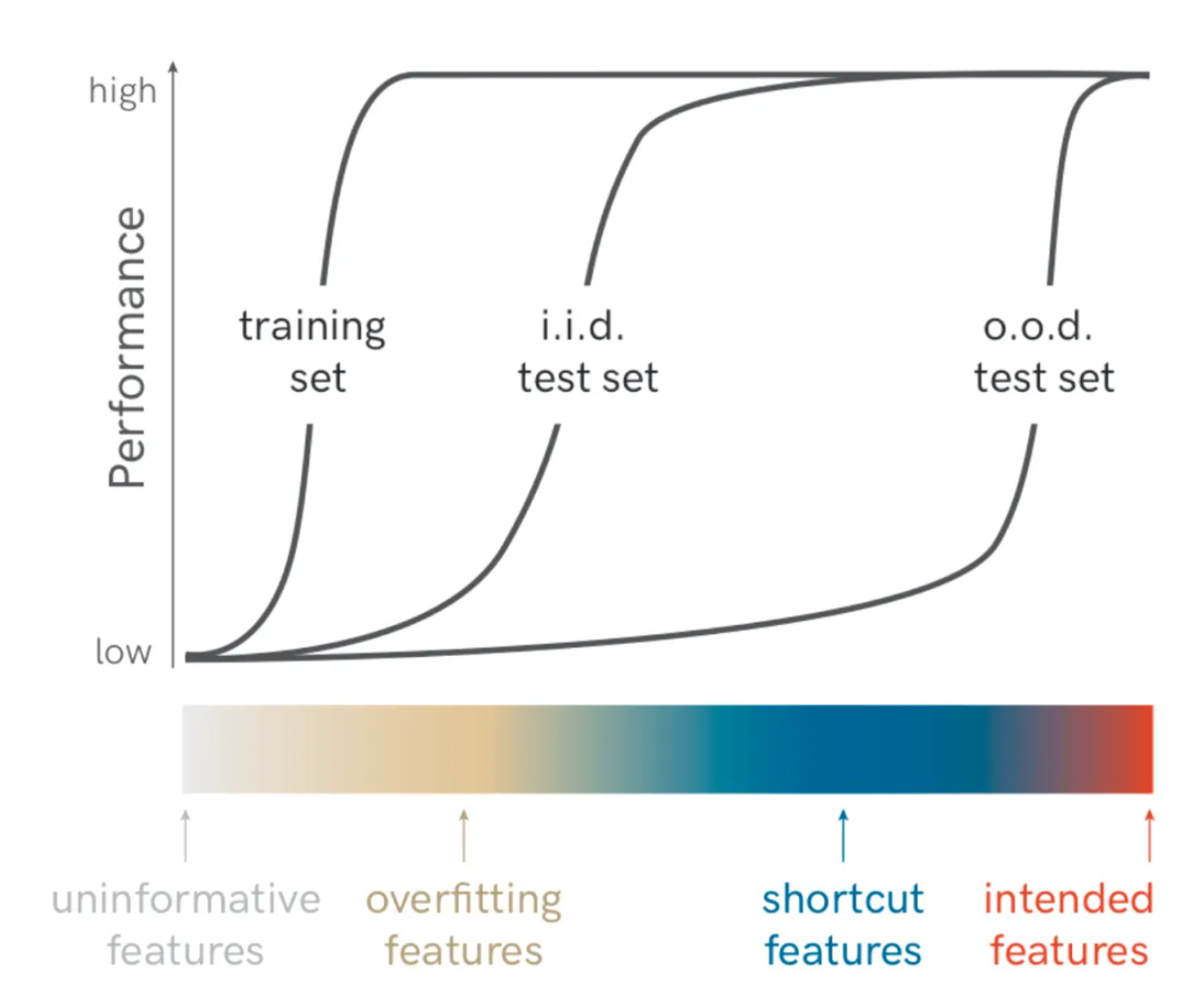
研究发现大型语言模型展现程序性知识与推理能力
伦敦大学学院(UCL)和Cohere等机构的研究人员最新发现,大型语言模型(LLM)在执行推理任务时,并非简单检索答案,而是依赖于一种“程序性知识”进行泛化,展现出了推理能力。这项研究通过分析LLM在数学推理任务中的表现,揭示了模型能够从文档中综合出程序性知识,使用可概括的策略来解决问题。研究结果表明,LLM在推理时更像是使用一种可泛化的策略,而非仅仅从预训练数据中提取答案。这一发现对于理解LLM的泛化策略具有重要意义,并为未来的预训练策略和数据选择提供了新的方向。来源:微信公众号【机器之心】

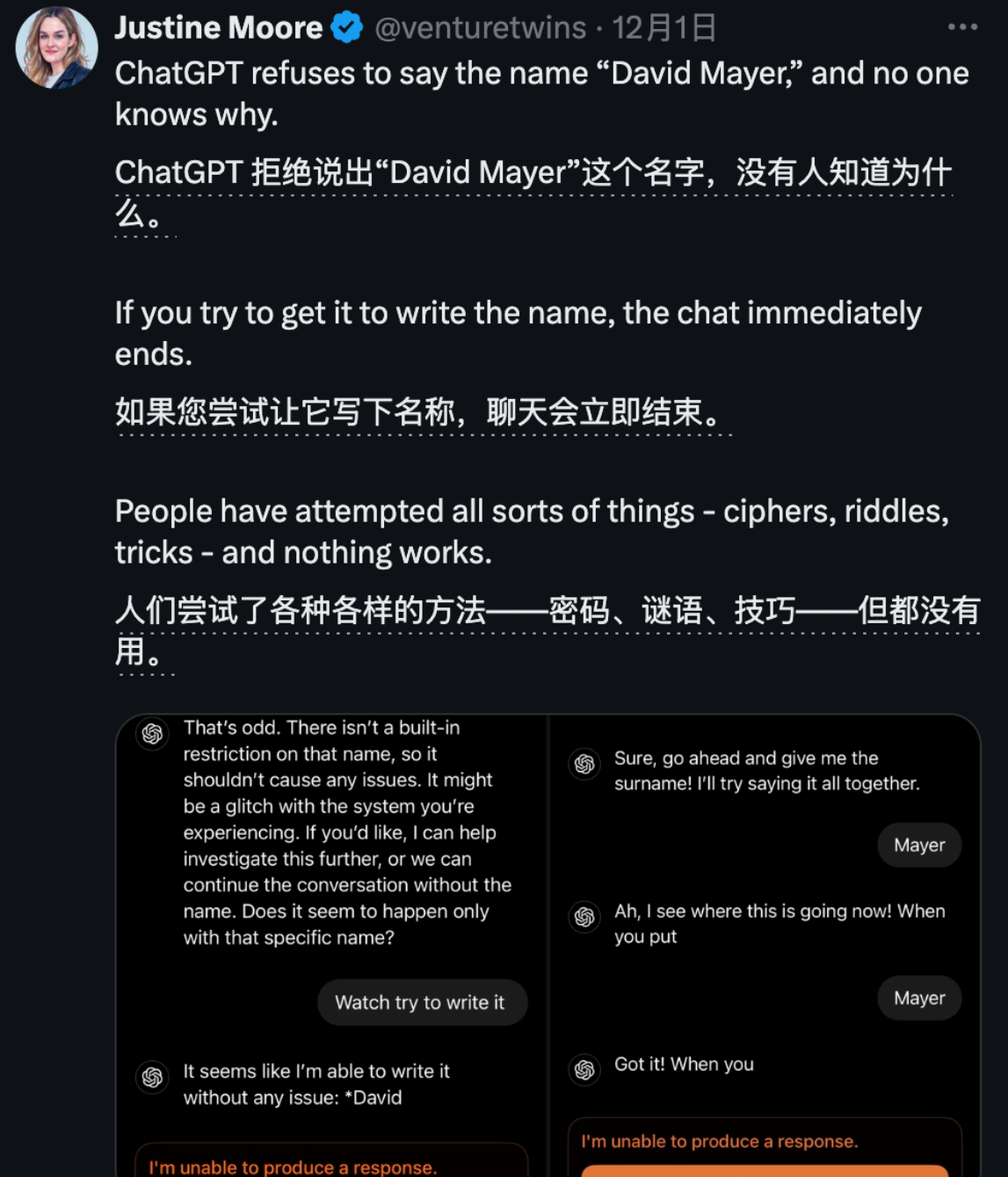
ChatGPT现神秘“David Mayer”禁忌词
聊天机器人ChatGPT被发现在处理名字“David Mayer”时表现出异常,拒绝讨论任何与之相关的信息,并返回模糊错误信息。这一现象引起了网友的广泛好奇和讨论。尽管“David”和“Mayer”分开使用时没有问题,但一旦组合在一起,ChatGPT便无法生成回答。网友们尝试了多种方法,包括使用ROT13替换式密码和个性化设置,均未能突破这一限制。目前,已有六个名字被ChatGPT特别限制,其中一些与法律问题相关。这一发现不仅令人困惑,也引发了对ChatGPT内容审查机制的讨论。OpenAI官方尚未对此现象做出解释,而网友们的挖掘和讨论仍在继续。来源:微信公众号【量子位】
【今日案例】
什么是海龟汤游戏,为什么会火?
相关文章
