2月18日·马斯克发布Grok-3,20万块GPU训练刷新AI性能记录
2月18日·周二 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在[图片]这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
马斯克发布Grok-3,20万块GPU训练刷新AI性能记录
马斯克带领xAI团队发布了最新的人工智能模型Grok-3。该模型在20万块GPU上训练,计算量是前代Grok-2的10倍,性能大幅提升。Grok-3在数学、科学问答和编码等多项基准测试中超越了DeepSeek-R1和Gemini-2 Pro等竞争对手,其推理模型Grok-3 Reasoning更是展现出强大的思维能力。此外,Grok-3还推出了智能体「DeepSearch」,可联网进行深入搜索,提供更透明的信息检索过程。马斯克表示,Grok-3将在一周内上线全部功能,并计划几个月内全面开源。Grok-3的发布标志着xAI在AI领域的重大突破,展现了其在技术创新和性能优化上的强大实力。来源:微信公众号【新智元】

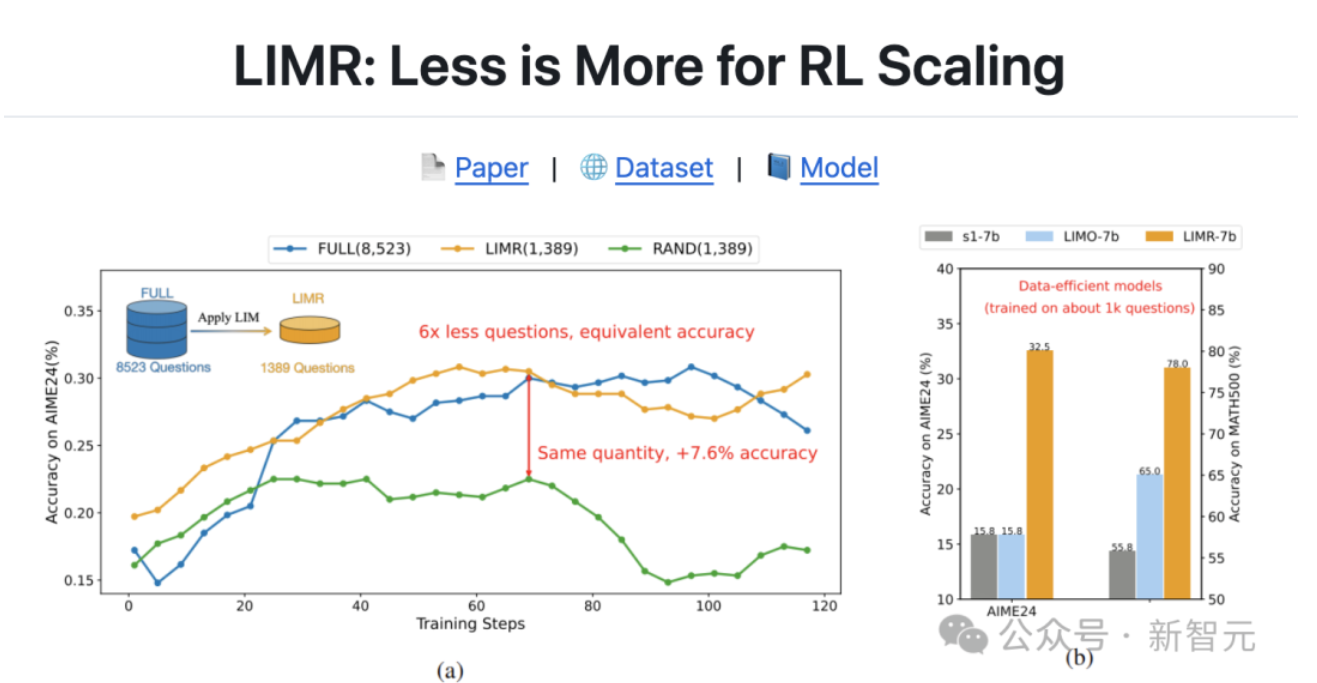
新研究挑战强化学习Scaling Law,数据质量胜过规模
强化学习中,数据量是否越多越好?最新研究提出了一种名为“学习影响测量”(LIM)的方法,颠覆了传统认知。研究发现,优化数据质量而非单纯扩大数据规模,能显著提升模型推理能力。通过分析训练样本的学习动态,LIM可识别对模型改进贡献最大的样本,从而实现高效的数据选择。实验表明,仅用1/6的数据量,LIM方法就能达到甚至超过传统大规模数据训练的效果。这一发现不仅为强化学习训练提供了新思路,还揭示了在数据稀疏和小模型场景下,强化学习结合高效数据选择策略的显著优势。该研究有望改写强化学习的Scaling Law,为AI模型训练带来新的突破。来源:微信公众号【新智元】
微软发布3.1T高质量数据集,多领域性能超越开源标准
微软推出RedStone数据处理管道,开源了3.1万亿token的高质量数据集,涵盖通用、代码、数学和问答等多个领域。RedStone通过优化数据处理流程,从Common Crawl中提取并清洗数据,构建了RedStone-Web、RedStone-Code、RedStone-Math和RedStone-QA等数据集。这些数据集在多项任务中显著提升了模型性能,超越现有开源数据集。例如,RedStone-Web在通用知识任务中表现优异,RedStone-Code在代码生成任务中显著增强了模型能力,RedStone-Math和RedStone-QA也在各自领域展现了更高的数据质量。RedStone的核心在于多层过滤系统,通过精细筛选确保数据的高质量和实用性。该数据集的开源为大模型的预训练和后训练提供了坚实支撑,推动了人工智能研究的发展。来源:微信公众号【新智元】

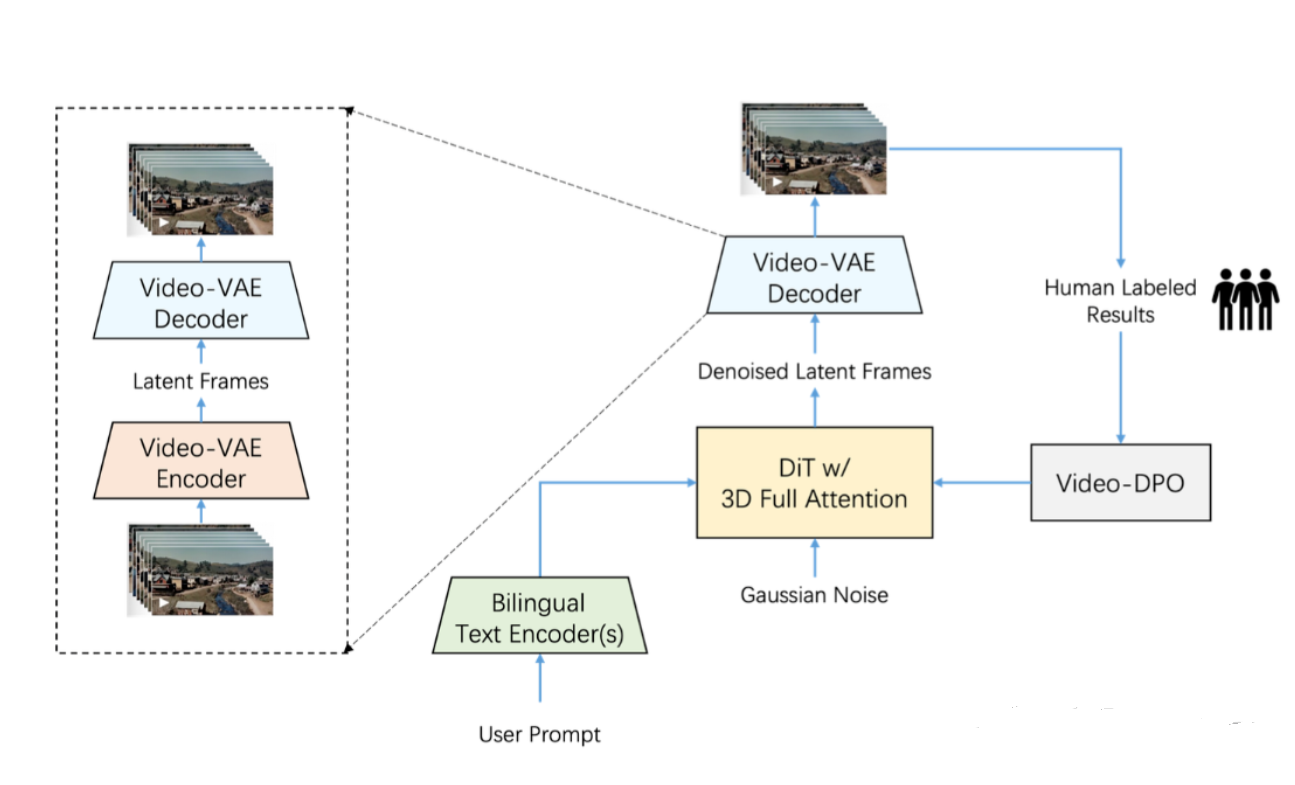
阶跃开源全球最大视频生成模型,多模态技术再突破
阶跃星辰联合吉利汽车集团开源了两款多模态大模型:全球参数量最大的开源视频生成模型Step-Video-T2V和首款产品级开源语音交互模型Step-Audio。Step-Video-T2V参数量达300亿,支持中英双语输入,可在复杂运动、美感人物和镜头语言等方面生成高质量视频,性能显著优于同类开源模型。Step-Audio在逻辑推理、创作能力和指令控制等维度表现出色,支持多种场景下的高质量对话。两款模型均采用宽松的MIT开源协议,可自由编辑和商业应用。此次开源标志着中国在多模态领域的技术突破,进一步推动了全球人工智能技术的普惠发展。来源:微信公众号【量子位】
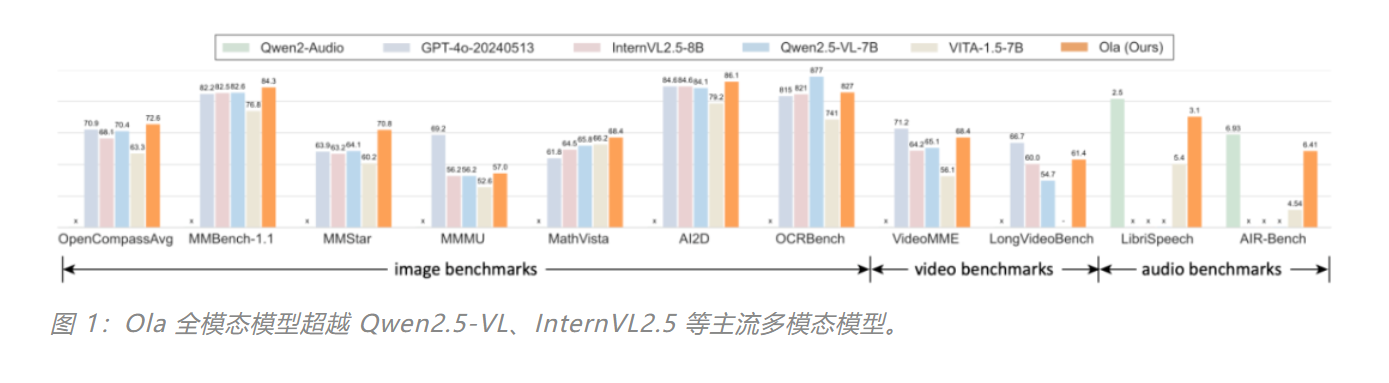
Ola-7B全模态模型发布,腾讯与清华联合打造多模态新标杆
腾讯混元Research、清华大学和南洋理工大学联合发布了Ola-7B全模态模型,该模型在图像、视频和音频理解等多模态任务中表现出色,超越了Qwen2.5-VL、InternVL2.5等主流模型。Ola-7B采用渐进式模态对齐策略,从图像和文本模态入手,逐步扩展到视频和音频,最终实现全模态理解。其架构支持全模态输入和流式语音生成,同时通过跨模态数据优化,显著提升了模型性能。Ola-7B在OpenCompass图像基准测试中平均准确率达到72.6%,在VideoMME视频理解测试中准确率达到68.4%,音频任务表现也接近专业音频模型水平。目前,Ola-7B的代码、模型和训练数据已开源,旨在推动全模态技术的进一步发展。来源:微信公众号【机器之心】
相关文章
