3月25日·DeepSeek-V3震撼上线,代码与数学性能飙升挑战GPT-5
3月25日·周二 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
DeepSeek-V3震撼上线,代码与数学性能飙升挑战GPT-5
DeepSeek-V3于2025年3月24日深夜悄然发布,参数量达6850亿,相较于上一版本提升显著。此次升级后,该模型在代码生成与数学推理能力上实现了质的飞跃,甚至在代码能力上追平了Claude 3.7。苹果机器学习工程师Awni Hannun基于MLX框架和4 – bit量化,成功在512GB M3 Ultra上实现超过20 token/s的运行速度,展现了其在消费级设备上的强大适配性。此外,DeepSeek – V3采用MIT开源协议,支持自由修改、分发以及商业化应用,为开发者提供了更大的自由度。其在多项测试中表现出色,不仅在代码生成上与Claude 3.7相媲美,还在数学竞赛题目解答等多维度测评中展现出强大的通用能力。DeepSeek – V3的上线,预示着全球AI格局的进一步重塑,其开源模式有望打破传统封闭生态的垄断,推动AI技术的普惠化发展。来源:微信公众号【新智元】
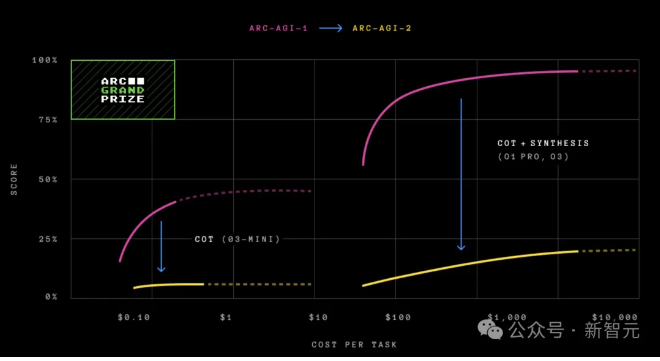
AI终极大考ARC-AGI-2发布,顶级模型集体“翻车”
Keras之父François Chollet宣布AI界“终极大考”ARC-AGI-2正式发布。这一测试旨在衡量AI与人类在解决复杂任务上的差距,结果却让人大跌眼镜:包括GPT-4.5、Claude 3.7 Sonnet、Gemini 2在内的基础大模型全部得0分,CoT推理模型得分也仅为4%。相比之下,人类测试者平均仅需5分钟即可解题,且400名参与测试的人类中,每项任务至少有两人能在两次尝试内成功解决。ARC-AGI-2的发布,不仅戳破了AGI(通用人工智能)的神话,还暴露了当前AI在符号解释、组合推理和上下文规则应用上的三大短板。与此同时,2025年ARC奖竞赛也于本周开启,总奖金高达100万美元,旨在激励研究人员探索新思路,推动开源项目发展,打造能够战胜ARC-AGI-2的系统。来源:微信公众号【新智元】
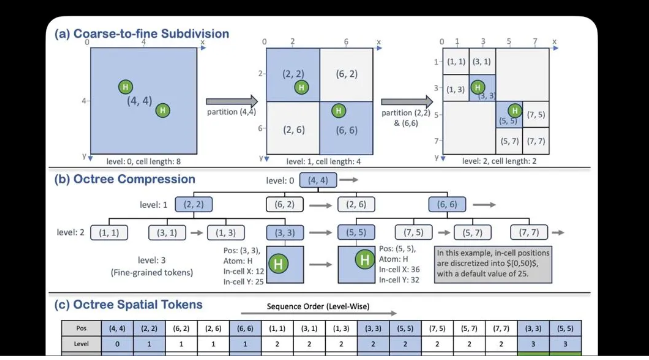
Uni-3DAR:用自回归技术统一微观与宏观3D世界,性能大幅提升
由深势科技、北京科学智能研究院及北京大学联合研发的Uni-3DAR模型正式发布。该模型通过自回归下一token预测任务,将微观(如分子、蛋白质)与宏观(如物体几何结构)的3D结构生成与理解任务统一起来,成为世界首个此类科学大模型。Uni-3DAR采用“粗到细”token化方法,将3D结构转化为一维token序列,解决了3D结构建模中数据表示不统一和建模任务不统一的两大痛点。实验表明,Uni-3DAR在分子生成、晶体结构预测等任务中性能显著提升,相比扩散模型,生成任务性能提升256%,推理速度加快21.8倍。未来,Uni-3DAR有望进一步扩展到宏观3D任务,并融合多模态数据,构建通用科学智能体,推动AI for Science的发展。来源:微信公众号【机器之心】
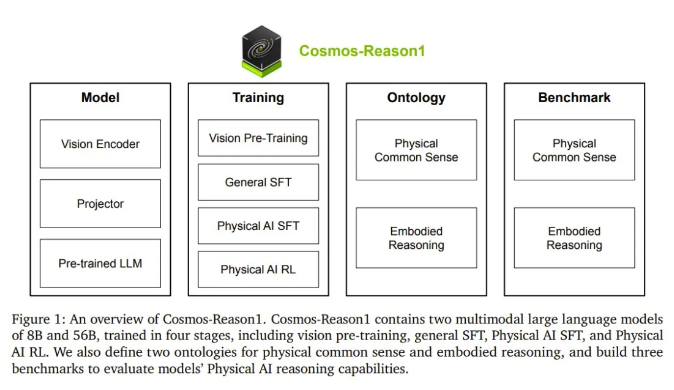
英伟达发布Cosmos-Reason1,具身推理能力大幅提升
英伟达近日推出了Cosmos-Reason1,一个专注于物理常识和具身推理的多模态模型套件。该模型包含8B和56B两个版本,经过视觉预训练、通用SFT、物理AI SFT和强化学习四个阶段的训练,能够生成有物理依据的响应。在视觉问答任务中,Cosmos-Reason1展现出对物理常识的理解能力,例如在面对没有正确答案的选项时,能够识别陷阱并拒绝选择。实验表明,Cosmos-Reason1在物理常识和具身推理任务上的表现超过了OpenAI的ο1模型。其多模态架构采用仅解码器设计,结合Mamba-MLP-Transformer混合架构,支持更长视频的训练。此外,英伟达还构建了物理AI推理的基准和本体论,推动具身推理在真实物理世界中的应用。来源:微信公众号【机器之心】
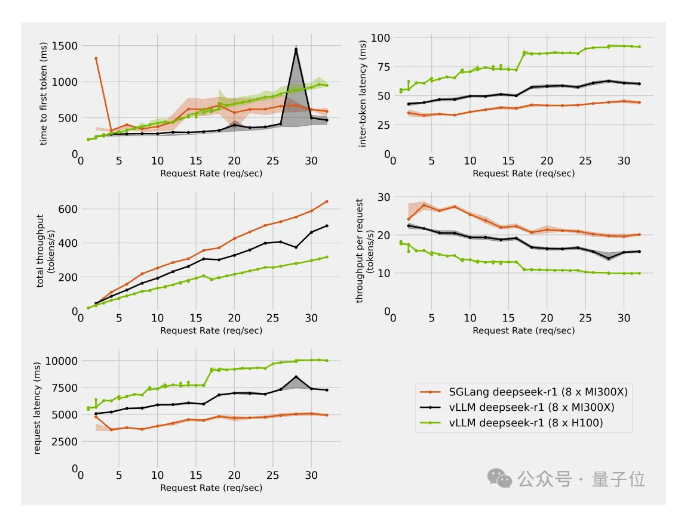
AMD MI300X跑DeepSeek性能超英伟达H200,吞吐量达五倍
AMD的MI300X在运行DeepSeek模型时表现出色,性能全面超越英伟达H200。测试结果显示,在相同延迟下,MI300X的吞吐量最高可达H200的五倍,相同并发下吞吐量比H200高出75%,延迟降低60%。如果需要Token间延迟不超过50毫秒,MI300X节点可处理128个并发请求,而H200节点仅能处理16个。这一成果主要得益于SGLang框架和AMD优化的AI内核库AITER。SGLang是一个开源大模型推理框架,拥有超过1.2万星标,适用于AMD和英伟达硬件。AITER则是一个高性能AI算子库,可显著提升MI300X的推理性能。此外,AMD还通过超参数调整进一步优化了系统性能,使其在大规模线程任务中表现更佳。此次AMD的表现,让其在AI硬件领域更具竞争力。来源:微信公众号【量子位】
相关文章
