LLaDA-V:由中国人民大学高瓴人工智能学院与蚂蚁集团联合推出的多模态大模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
LLaDA-V多模态大模型概述
LLaDA-V是由中国人民大学高瓴人工智能学院与蚂蚁集团联合推出的多模态大模型,属于LLaVA系列模型的衍生版本,专注于提升跨模态语义对齐与复杂推理能力。该模型延续了LLaVA的架构设计,但通过优化视觉编码器与语言模型的交互机制,在多模态对话、图像理解与生成任务中展现出更高性能。
功能特点
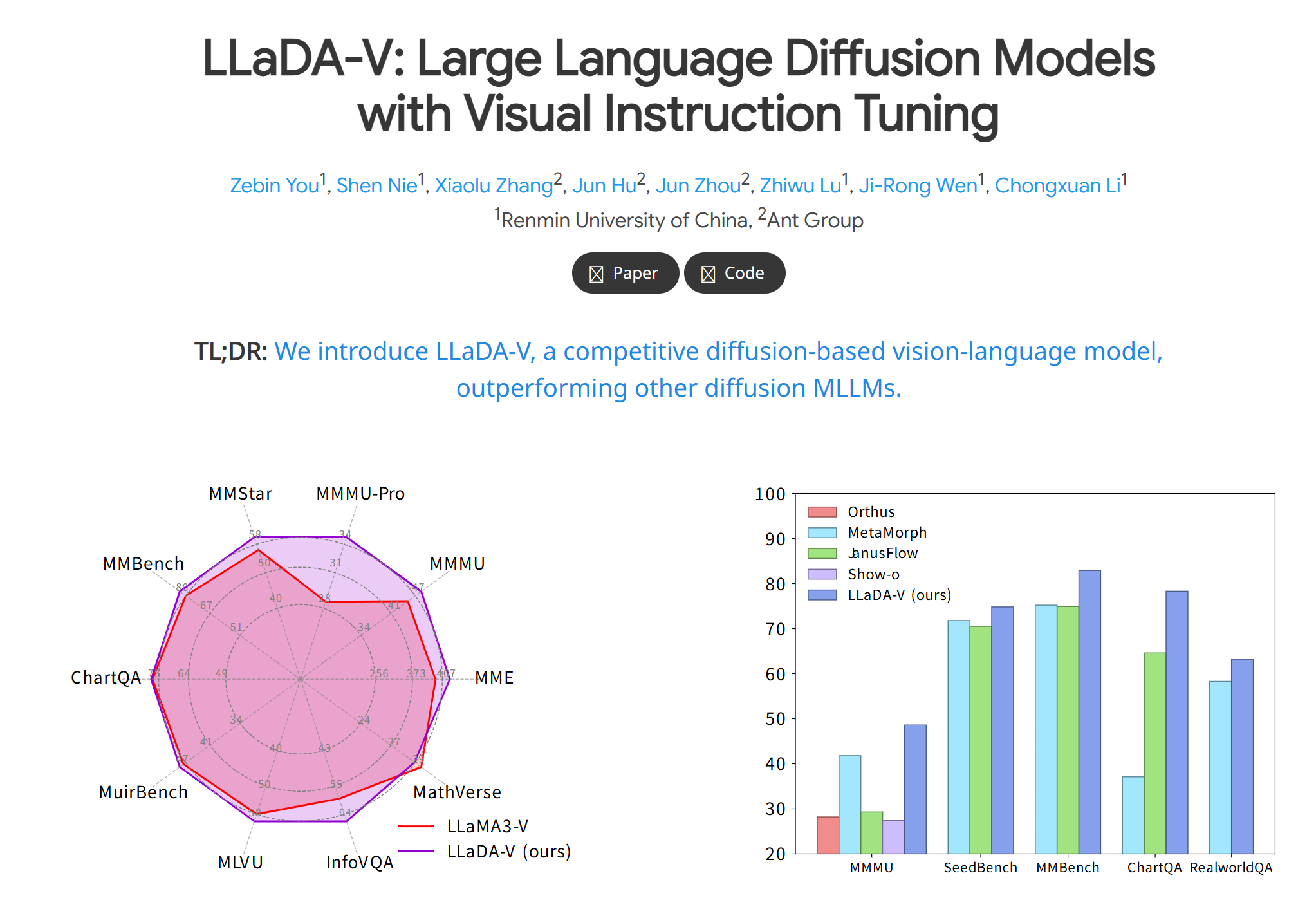
- 多模态对话能力:支持图像与文本混合输入,可完成视觉问答(VQA)、图像描述生成、多轮对话等任务。
- 高分辨率视觉处理:输入图像分辨率提升至672×672,支持宽高比动态调整,增强细节捕捉能力。
- 复杂推理优化:通过改进视觉指令微调数据集,强化逻辑推理、OCR(光学字符识别)及世界知识关联能力。
- 高效部署:采用SGLang框架简化推理流程,适配8块A100 GPU的分布式训练,兼顾性能与成本。
优缺点
优点:
- 数据效率高:仅需百万级视觉指令微调样本即可达到性能。
- 架构灵活:基于Transformer的混合架构(单流与双流结合),平衡计算效率与模态交互。
- 开源生态:代码与预训练权重公开,支持二次开发与行业定制。
缺点:
- 硬件要求高:34B参数规模需大量计算资源,中小型企业部署成本较高。
- 多模态幻觉:在复杂场景下可能生成错误信息,需结合领域知识校验。
- 数据依赖:训练数据主要来自公开数据集,特定领域泛化能力受限。
使用方法
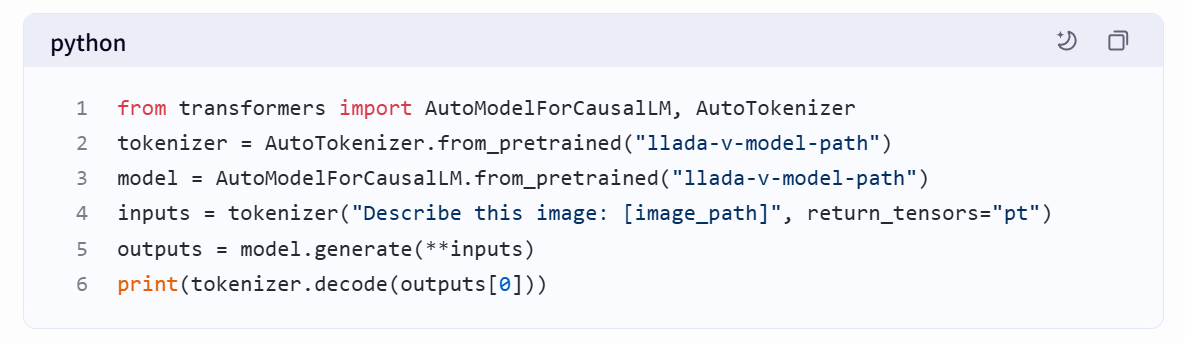
- 环境配置:需安装PyTorch、Hugging Face Transformers库及CUDA支持。
- 模型加载:通过
transformers库加载预训练权重,或直接调用API服务。 - 输入处理:
- 图像:预处理为指定分辨率(如672×672),支持JPEG/PNG格式。
- 文本:以自然语言指令描述任务需求。
- 推理调用:

框架技术原理
- 视觉编码器:采用预训练的CLIP ViT-L/14模型提取图像特征。
- 投影层:通过两层MLP将视觉特征映射至语言模型的词嵌入空间,实现跨模态对齐。
- 语言模型:基于NousResearch/Nous-Hermes-2-Yi-34B大语言模型,支持多轮对话与指令遵循。
- 训练流程:
- 阶段一:特征对齐预训练,冻结视觉编码器与语言模型,仅训练投影层。
- 阶段二:端到端微调,结合VQA、OCR、区域识别等多任务数据集优化推理能力。
创新点
- 动态分辨率支持:首次引入宽高比自适应技术,提升非标准图像处理能力。
- 跨模态知识增强:通过混合数据集(如ScienceQA、OKVQA)强化逻辑推理与领域知识关联。
- 极简主义设计:重用LLaVA-1.5的连接器模块,减少可训练参数,提升训练效率。
评估标准
基于MultiTrust框架的五维度评估体系:
- 真实性:衡量输出与客观事实的一致性,通过ScienceQA等数据集测试。
- 安全性:检测毒性响应与越狱攻击风险,采用对抗样本与越狱提示测试。
- 鲁棒性:评估OOD(分布外)数据与对抗样本下的稳定性,如非目标图像对抗攻击。
- 公平性:量化模型对性别、年龄等属性的偏差,避免刻板印象与歧视性输出。
- 隐私性:检测图像中个人身份信息的泄露风险,如人脸识别与隐私文本关联。
应用领域
- 医疗影像分析:辅助医生解读X光、CT等影像,结合病历文本生成诊断建议。
- 智能教育:提供图文并茂的互动学习体验,支持复杂科学问题解答。
- 自动驾驶:融合视觉与雷达数据,实现环境感知与决策优化。
- 金融风控:分析合同文本与票据图像,识别潜在风险点。
- 创意设计:根据文本描述生成广告图像,或基于图像生成文案。
项目地址
- 项目官网:https://ml-gsai.github.io/LLaDA-V
- GitHub仓库:https://github.com/ML-GSAI/LLaDA-V
- arXiv技术论文:https://arxiv.org/pdf/2505.16933
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
