DeepSeek-R1-0528 : DeepSeek 开源的最新版 R1 模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
DeepSeek-R1-0528 是 DeepSeek 开源的最新版 R1 模型,在数学推理、代码生成、逻辑推理等多个核心基准测试中展现出开源模型当前最先进的性能水平。该模型通过后训练阶段的重度优化,在未改动模型结构的情况下,实现了思维深度的质变,成为开源领域高性能推理模型的新标杆。
功能特点
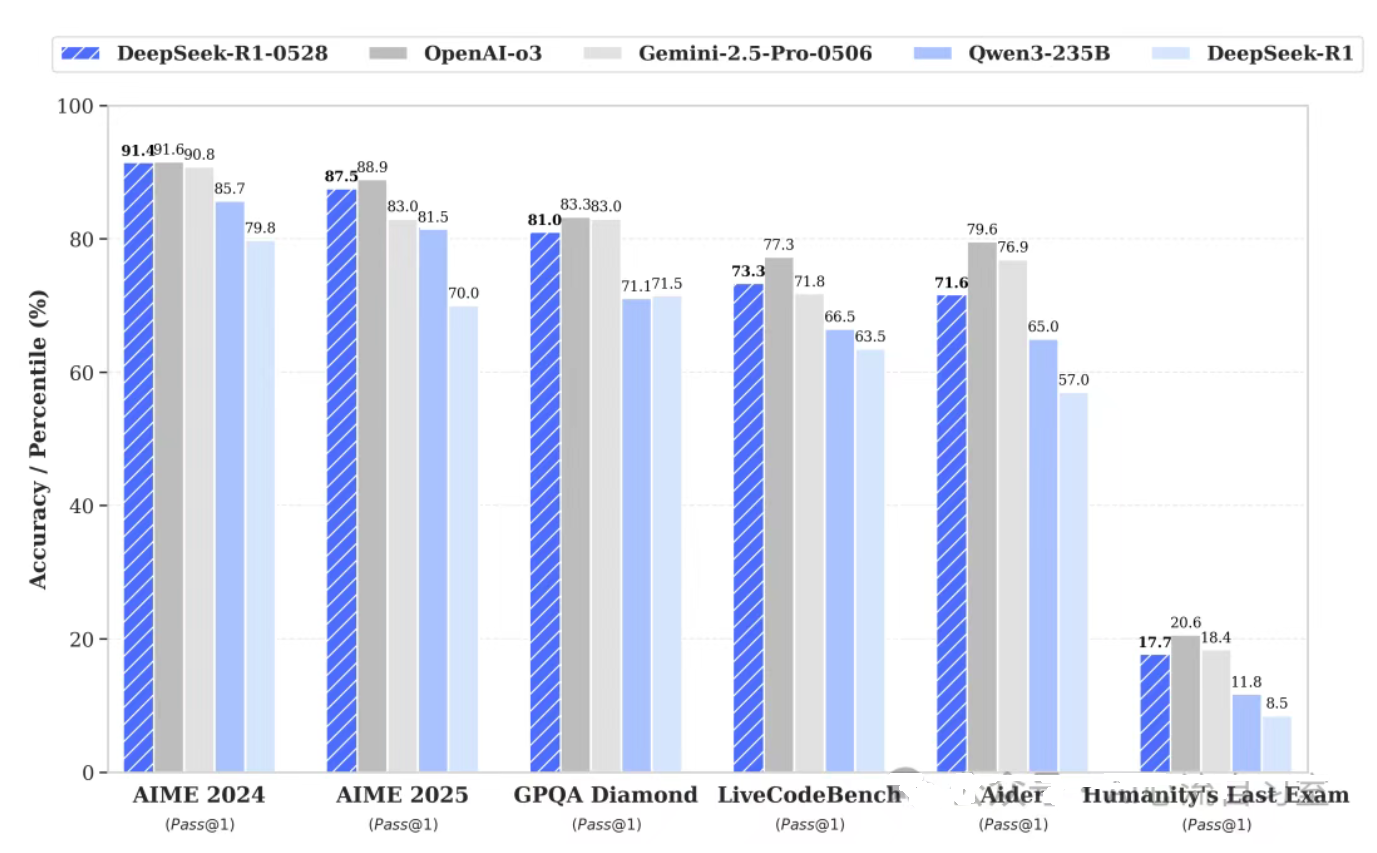
- 强大的推理能力:在数学推理方面表现卓越,AIME 2025 测试准确率从 70%提升至 87.5%,能够稳定给出正确答案,推理过程更加深入。在逻辑推理等任务中也有出色表现,可对复杂问题持续推理,生成逻辑严谨、表达自然的长文本内容。
- 优秀的代码生成能力:代码生成能力跃居全球第四,仅次于 OpenAI 的 o4 mini 和 o3 模型,成功超越了阿里巴巴的 Qwen 3 和马斯克旗下 xAI 的 Grok 3 mini。生成的代码更为结构化、可读性强且 bug 极少,能够一次性生成超过千行无误代码,并在前端 UI 构建、JS 动画等任务中展现出更高精度。
- 支持长上下文窗口:支持 128K 超大上下文窗口,推理过程可长达 30 至 60 分钟,能够处理更复杂的任务和更长的文本内容。
- 幻觉率降低:幻觉率降低了 45% – 50%,结果更准确可靠,通过事实锚定技术和置信度校准等方法,减少了模型编造细节的情况。
- 多轮对话稳定性提升:通过优化思维链技术,在 20 轮以上的复杂对话场景中,上下文一致性得到显著提升,幻觉问题减少了 30%,特别是在医疗、法律等专业领域展现出更出色的表现。
优缺点
优点:
- 性能卓越:在多个任务上达到或接近领先模型的性能水平,为开源社区提供了高性能的推理模型选择。
- 开源免费:保持全量权重 MIT 许可,对开发者保持零门槛,保证了兼容性与易用性,降低了开发者的使用成本。
- 功能多样:具备强大的推理、代码生成、长文本处理等能力,可满足不同场景下的需求。
- 持续优化:通过后训练阶段的重度优化,不断提升模型的性能和稳定性,为用户提供更好的使用体验。
缺点:
- 响应速度较慢:在处理一些任务时,推理时间较长,例如一道简单数学题需 963 秒推理(旧版约 200 秒),这可能会影响用户体验,尤其是在对实时性要求较高的场景中。
- 存在物理引擎参数调优盲区:在生成“3D 多米诺骨牌模拟”等涉及物理引擎的任务时,多次尝试仍输出不可运行代码,暴露出其在物理引擎参数调优上的不足。
- 开源版本安全性有待提高:开源版本仍易被越狱(安全绕过率超 60%),企业部署需外挂安全层,增加了企业的部署成本和安全风险。
如何使用
- 官方入口:目前,新版 R1 有 3 个直接可用的官方入口,包括网页端、App 和微信小程序(直接搜 DeepSeek),用户可以根据自己的需求选择合适的入口进行使用。
- 官方 Api:官方 Api 已经更新,入口为 https://platform.deepseek.com/sign_in,开发者可以通过调用官方 Api 来使用 DeepSeek-R1-0528 模型的功能。
- 华为云 MaaS 平台:华为云已针对该模型完成了基于昇腾 AI 云服务的深度适配与优化,并正式上线华为云 ModelArts Studio 大模型即服务平台(MaaS)。开发者可通过华为云,一键调用 DeepSeek-R1-0528 API 服务,实现便捷调用。平台提供实时监控、日志分析等运维能力,简化流程。同时,该平台还提供按需使用的弹性算力,有效帮助企业控制算力成本,实现最优成本。
- 腾讯云:腾讯云也上线了 DeepSeek-R1-0528,企业和开发者可以通过腾讯云直接调用 API 接口,获得稳定优质的服务;也可以通过腾讯云智能体开发平台内置的 RAG、工作流和智能体开发的能力,快速搭建专属智能体应用;此外,还能通过腾讯云 TI 平台对模型进行精调。
框架技术原理
- 后训练阶段重度优化:通过增加训练算力投入,新版后训练投入算力远超旧版,驱动模型探索更复杂推理路径。在 AIME 数学测试中,单题平均 token 使用量从 12K → 23K(+91.7%),思考步骤更细化、验证更严谨。
- 思维链自进化:从单线推理到多路径验证,对同一问题生成多条推理链,择优输出,并在每步推导后插入逻辑验证节点(如维度检查、边界条件确认),提高了推理的准确性和可靠性。
- 注意力机制优化:采用多头潜在注意力(MLA),前 3 层 KV 缓存联合压缩,减少 5 – 13%显存占用,低秩近似保留关键信息,避免长程依赖退化。
- 上下文扩展:使用 YaRN 位置编码改进 RoPE 旋转编码,通过频域插值支持 128K 上下文(开源版),相比 NTK 方法,在超长文本任务中位置感知更稳定。
- MoE 动态路由优化:685B 总参数中,单 token 仅激活 37B(5.4%利用率),在保证模型性能的同时,降低了计算资源的消耗。
创新点
- 推理能力提升不依赖架构革新:通过定向增强思考深度与验证强度,结合算力密集型后训练,使中等规模模型亦可比肩顶级闭源产品,证明了推理能力的跃迁未必依赖架构革新。
- 支持长时间思考:支持单任务连续思考 30 – 60 分钟,这是其最颠覆性的突破之一,通过注意力机制优化、上下文扩展和 MoE 动态路由优化等技术协同实现。
- 代码生成架构升级:具备项目级上下文感知能力,能够理解跨文件依赖(如 import 关系、配置文件继承);采用语法树约束解码,输出符合作业抽象语法树(AST),降低运行时错误;还具备工程化能力增强和调试能力内化等特点,可一次生成可运行项目,如贪吃蛇游戏(完整 HTML/CSS/JS)、单词评分系统(含测试脚本),并能进行跨语言转换和自动添加 API 文档字符串与功能注释。
- 幻觉抑制与安全对齐:采用事实锚定技术,对摘要/改写任务,强制检索相似真实文本片段作为参考;进行置信度校准,对低概率输出施加惩罚,避免“编造细节”;在 RL 阶段加入有害输出检测器(如暴力/偏见内容),提升了模型的安全性与可控性。
- 思维链蒸馏与小模型赋能:通过知识蒸馏带动了小模型崛起,例如 8B 小模型性能飞跃,蒸馏版 Qwen3 – 8B 在 AIME 2024 超越原模型 10%,逼近 235B 大模型,证明了推理能力可脱离规模独立迁移,为边缘计算打开可能。
评估标准
- 数学推理能力:使用 AIME(美国数学邀请赛)等数学测试数据集进行评估,以准确率为主要指标,DeepSeek-R1-0528 在 AIME 2025 测试中准确率从 70%提升至 87.5%。
- 代码生成能力:采用 LiveCodeBench 等代码能力评估平台进行评估,以代码的完整性、可读性、正确性以及在测试中的排名等为指标,R1-0528 的代码生成能力跃居全球第四。
- 逻辑推理能力:通过 Extended NYT Connections 等基准测试进行评估,该测试基于《纽约时报》的 Connections 谜题游戏,包含了 651 个 NYT Connections 谜题,并且增加了额外的词汇以提高难度,旨在更全面地测试模型的语言理解和推理能力,R1-0528 在此测试中表现优异。
- 长文本处理能力:以支持的最大上下文窗口长度和处理长文本任务的准确性、稳定性等为指标进行评估,R1-0528 支持 128K 超大上下文窗口,在处理长文本任务时表现出色。
- 幻觉率:通过人工评估或自动评估方法,统计模型生成内容中与事实不符或编造细节的比例,R1-0528 的幻觉率降低了 45% – 50%。
- 多轮对话稳定性:在 20 轮以上的复杂对话场景中,评估上下文一致性和幻觉问题的出现频率,R1-0528 的上下文一致性得到显著提升,幻觉问题减少了 30%。
应用领域
- 学术研究:可用于数学、计算机科学等领域的学术研究,帮助研究人员进行数据分析和模型验证。
- 软件开发:为开发者提供强大的代码生成和调试能力,可辅助开发各种类型的软件项目,提高开发效率和质量。
- 智能客服:凭借其优秀的语言理解和推理能力,可用于构建智能客服系统,能够更准确地理解用户的问题并给出合理的回答。
- 内容创作:在文学创作、新闻写作等领域发挥作用,为创作者提供灵感和辅助创作,提高内容创作的效率和质量。
- 教育领域:可作为教学辅助工具,帮助学生解答数学问题、编写代码等,提高学习效果。
项目地址
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528/tree/main
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
