星火X2-Flash : 科大讯飞推出的MoE架构大语言模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
星火X2-Flash是科大讯飞于2026年4月29日发布的基于混合专家(MoE)架构的大语言模型,总参数量达30B,支持最大256K上下文窗口,专为智能体(Agent)时代设计。该模型依托华为昇腾910B国产算力集群训练完成,在智能体任务执行、代码生成、长文本处理等场景中表现接近万亿级参数模型,同时通过技术创新大幅降低开发成本,推动国产大模型生态建设。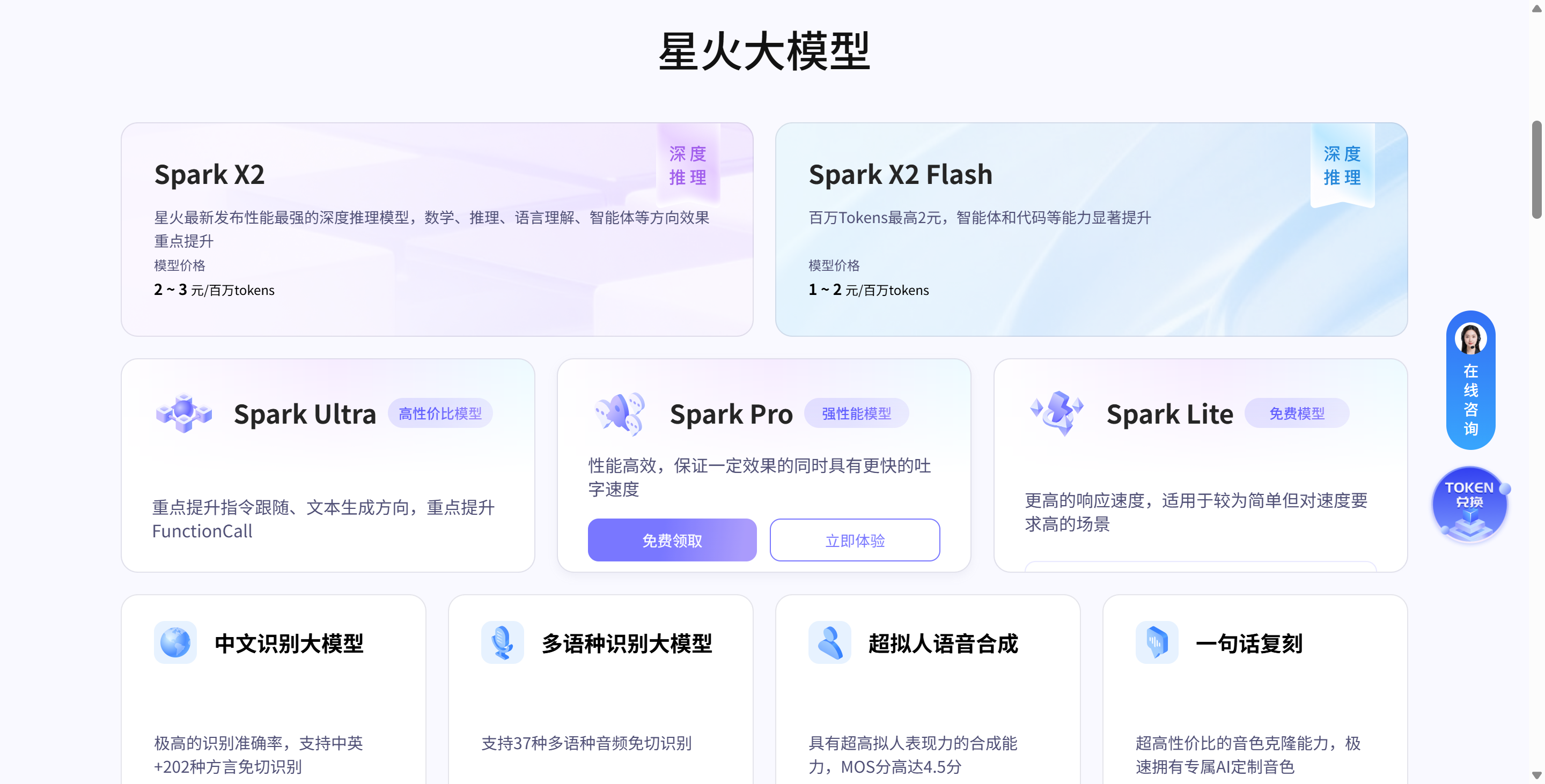
功能特点
- 超长上下文支持:256K上下文窗口可处理超长文档、复杂任务链,满足智能体长链路需求。
- 智能体任务优化:深度研究报告生成、Skill管理与调用、系统控制与执行等任务效果接近国际顶尖模型。
- 代码生成能力:可快速生成复杂Skill(如AI视频生成),提供结构定义、核心功能及使用案例。
- 低成本高效能:相同工作流下Token消耗仅为主流大模型的1/3,降低开发者构建复杂应用的成本。
- 国产算力适配:基于昇腾910B集群训练,通过DSA(稀疏注意力)与MTP(多Token预测)技术优化训练效率,解决国产芯片长文本训练慢的痛点。
- 多框架兼容:深度兼容OpenClaw、Claude Code等主流Agent框架,支持星辰Agent平台及AstronClaw、Loomy等应用接入。
优缺点
- 优点:
- 性价比高:性能接近万亿级模型,但成本显著降低。
- 国产自主可控:基于国产算力生态,减少对外部技术依赖。
- 长文本处理能力强:256K上下文支持复杂任务场景。
- 推理效率优化:采样解码效率提升2倍以上,缓解长交互场景性能瓶颈。
- 缺点:
- 模型规模较小:30B参数在通用能力上可能弱于更大规模模型。
- 生态成熟度待提升:虽兼容主流框架,但开发者社区规模需进一步扩大。
如何使用
- API调用:通过讯飞开放平台或星辰MaaS平台申请API权限,获取密钥后即可调用模型接口。
- 平台接入:在AstronClaw、Loomy等已集成星火X2-Flash的应用中直接使用,无需额外开发。
- 场景适配:根据需求选择智能体任务、代码生成或长文本分析等功能模块,参考官方文档配置参数。
框架技术原理
星火X2-Flash采用MoE架构,将模型拆分为多个专家子网络,通过门控机制动态分配任务至最适配的专家,提升计算效率。其核心技术创新包括:
- DSA+MTP技术:结合稀疏注意力机制与多Token预测,优化长文本训练效率,使256K上下文训练效率提升4.5倍。
- 国产算子优化:针对昇腾910B芯片设计定制化算子,减少计算冗余,提升硬件利用率。
- 分布式训练策略:通过分层通信、低精度KVCache等技术,实现集群训练效率从20%提升至90%。
创新点
- 国产算力突破:首次在国产芯片上实现256K上下文高效训练,解决长文本训练慢的难题。
- 智能体数据闭环:构建可验证的大规模智能体数据自动合成平台,由Agent自主搭建环境、检测结果准确性,实现数据高效合成与闭环。
- 强化学习优化:通过算法与工程创新,将采样推理效率提升2倍以上,为大规模强化学习训练扫清算力障碍。
评估标准
- 任务效果:在深度研究报告、Skill管理、系统控制等复杂任务中,与万亿级参数模型对比准确率与完整性。
- 成本效率:测量相同工作流下的Token消耗量及推理速度,评估性价比。
- 长文本能力:通过256K上下文窗口处理超长文档,测试摘要、提取与问答的准确性。
- 框架兼容性:验证与主流Agent框架的集成度及功能覆盖范围。
应用领域
- 智能体开发:支持复杂Skill生成、多步骤任务拆解与执行,适用于企业级自动化流程。
- 代码生成:辅助编写脚本、系统命令及自动化运维代码,提升开发效率。
- 长文档分析:处理超长论文、报告,实现摘要生成、信息提取与问答交互。
- 多模态任务编排:作为Agent大脑,调度文生视频、图生视频等多平台工具链(如可灵、Runway、Pika等)。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
