One-Eval : 北大开源的自动化大模型评测框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
One-Eval 是北京大学 OpenDCAI 团队于 2026 年 4 月开源的自动化大模型评测框架,旨在解决传统评测方法依赖人工操作、流程繁琐、透明度低等问题。该框架基于自然语言驱动的智能体模式,用户只需用自然语言描述评测需求,系统即可自动完成基准推荐、数据下载、模型推理、指标计算及报告生成,实现全链路自动化评测。其设计目标是降低评测门槛,提升效率,同时通过全局状态追踪和人工在环机制确保评测过程的透明性与可控性。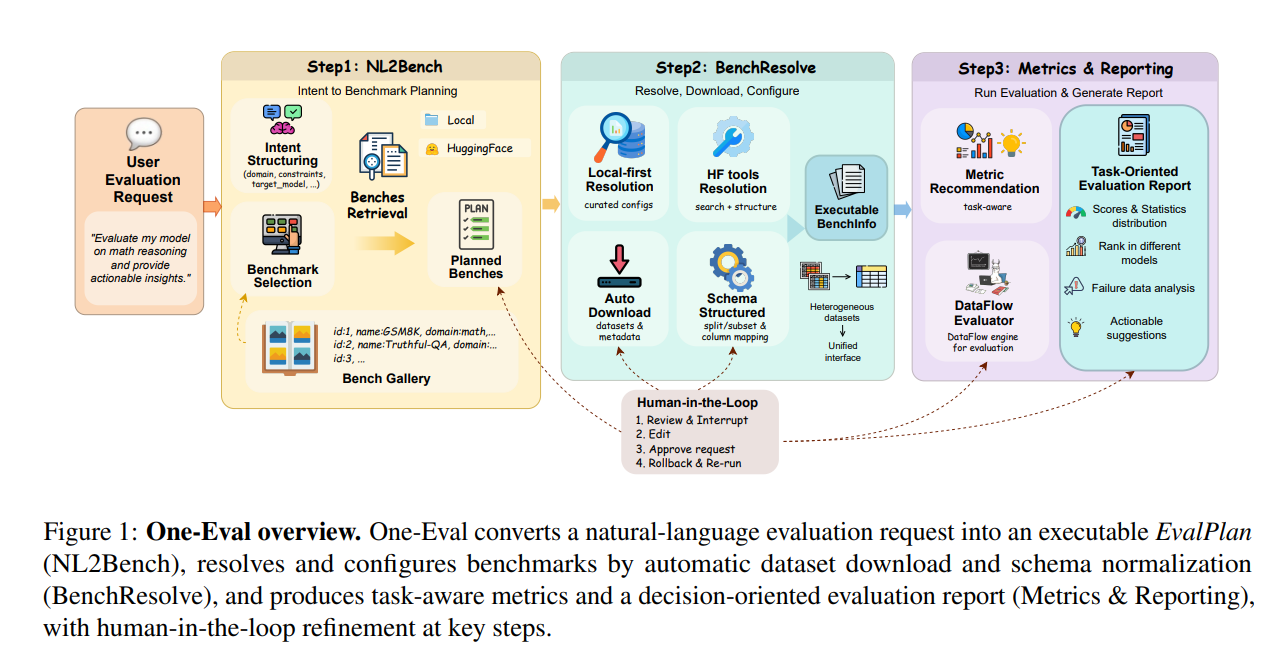
功能特点
- 自然语言驱动评测:用户通过自然语言描述需求(如“评测模型在数学推理任务上的表现”),系统自动解析并生成评测方案。
- 基准库管理:内置 GSM8K、MATH、MMLU、C-Eval 等主流评测基准,支持动态搜索 HuggingFace 平台上的最新数据集。
- 端到端自动化执行:自动完成数据下载、模型推理、答案评分、统计分析与报告生成,减少人工干预。
- 人机协同干预:在关键节点(如基准选择、参数配置)支持人工审查、编辑与重跑,确保评测策略的准确性。
- 异构数据统一接口:通过 DataFlow 引擎标准化不同数据集的格式与列映射,解决数据兼容性问题。
- 全局状态追踪:每一步执行状态持久化,支持断点恢复、回溯重跑与失败数据分析,提升评测可追溯性。
优缺点
- 优点:
- 高效性:将传统评测流程从数小时缩短至 10 分钟内,显著提升效率。
- 易用性:自然语言交互降低使用门槛,无需编写代码或配置复杂参数。
- 透明性:全局状态追踪与人工在环机制确保评测过程可解释、可控制。
- 灵活性:支持私有数据集与自定义指标接入,满足多样化评测需求。
- 缺点:
- 领域覆盖有限:当前内置基准主要聚焦文本类任务,对多模态任务及复杂软件工程能力(如代码执行测试)支持不足。
- 依赖外部模型 API:推理阶段的计算与 Token 消耗取决于用户选用的外部模型服务,可能产生额外成本。
如何使用
- 环境准备:通过 Conda 或 uv 创建虚拟环境,运行
pip install -e .安装依赖。 - 启动服务:
- 后端:运行
uvicorn one_eval.server.app:app --host 0.0.0.0 --port 8000启动 FastAPI 服务。 - 前端:进入
one-eval-web目录,执行npm install && npm run dev,访问localhost:5173。
- 后端:运行
- 配置参数:在 Web 界面设置 API Key(用于模型调用)、目标模型及 HuggingFace Token(用于数据集下载)。
- 发起评测:在输入框用自然语言描述需求(如“评测模型在金融领域的表现”),系统自动执行并生成报告。
- 人工干预:在关键节点(如基准确认)根据系统提示进行审查或修改,确保评测策略符合预期。
框架技术原理
- NL2Eval 智能解析:基于 LangGraph 构建状态机工作流,将自然语言需求拆解为结构化评估意图(如评估领域、能力重点、执行约束)。
- BenchResolve 基准解析:采用“本地优先,动态后备”策略,优先加载本地预置配置,缺失时自动调用 HuggingFace 工具搜索并结构化数据集元信息。
- DataFlow 算子系统:通过 DataFlow 引擎处理数据准备与流式计算,实现异构数据集的统一接入与转换,解决字段映射与格式兼容性问题。
- Metrics & Reporting 指标计算:支持多维度指标(如准确率、数学等价性检验、推理效率评估)与可视化报告生成,提供错误模式分析与案例级详细分析。
创新点
- 自然语言驱动评测:以智能体模式替代复杂脚本操作,实现交互降维,使评测流程更贴近人类思维方式。
- 全局状态总线架构:记录评测全生命周期状态,实现全链路可追溯与错误断点定位,提升评测透明度。
- 人工在环机制:在关键决策点保留人工审核环节,平衡自动化效率与专业干预需求,确保评测结果严谨性。
- 模块化设计:支持私有数据集与自定义指标轻松接入,满足不同场景下的定制化评测需求。
评估标准
- 任务效果:在数学推理、代码生成、长文本处理等任务中,与主流模型对比准确率、召回率等核心指标。
- 效率:测量从需求输入到报告生成的平均耗时,评估自动化流程的提速效果。
- 成本:统计评测过程中模型推理的 Token 消耗及计算资源使用量,分析成本效益。
- 透明性:通过全局状态追踪与人工在环机制,评估评测过程的可解释性与可控性。
- 扩展性:验证框架对私有数据集、自定义指标及新评测基准的接入能力。
应用领域
- 模型选型初筛:快速对比多个候选模型在数学、推理、代码、指令遵循等维度的表现,辅助模型选择。
- 私有化模型验收:对自部署或微调后的模型进行标准化能力验收与回归测试,确保模型质量符合预期。
- 基准调研:通过 Bench Gallery 快速检索与配置适合特定任务类型的评测集,支持学术研究与实践应用。
- 学术研究:为论文实验提供可复现、可追踪的自动化评测流水线,降低评测流程的重复劳动。
- Agent 能力评估:评测大语言模型在工具调用、规划与复杂任务执行中的表现(未来支持 SWE-bench 等场景)。
项目地址
- GitHub 仓库:https://github.com/OpenDCAI/One-Eval
- arXiv 技术论文:https://arxiv.org/pdf/2603.09821
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
