SenseNova-U1-8B-MoT-Infographic : 商汤科技开源的信息图增强模型
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
2026年5月底,商汤科技在开源SenseNova U1统一架构模型后,进一步发布了SenseNova-U1-8B-MoT-Infographic(信息图增强版)。这是一款专门针对信息图生成场景优化的8B参数开源模型,基于原生统一架构SenseNova-U1-8B-MoT,通过高质量专项数据训练与RL强化学习,在高密度文字渲染、版式稳定性、图表数据正确性三个核心维度上实现了显著突破。模型采用Apache 2.0协议完全开源,权重全开,支持商用,消费级GPU即可部署,社区已自发提供GGUF量化版本。在BizGenEval和IGenBench等信息图权威基准上,其表现超越了GPT-Image-1.5、Qwen-Image-2.0等闭源商业模型,被业界视为开源社区在信息图生成领域迈出的关键一步。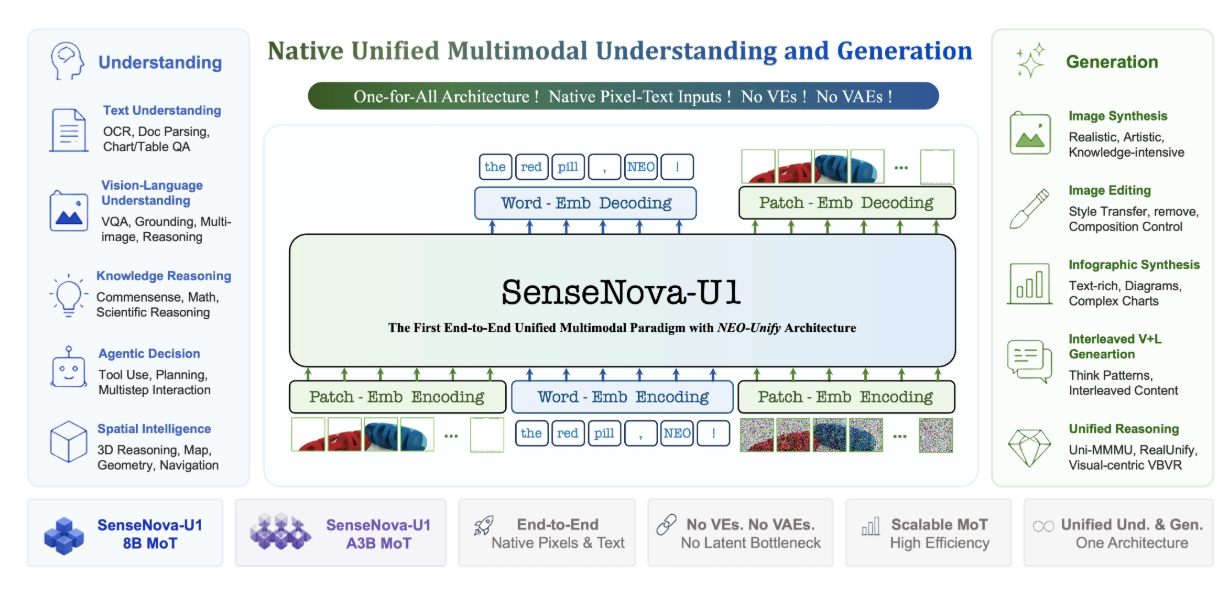
功能特点
- 高密度文字渲染:通过RL强化学习专项优化,脚注、表格注释、列表编号等小字场景清晰可读,解决了开源模型长期存在的”糊成一团”问题
- 版式稳定性增强:多模块信息图的对齐、留白、层级关系更加稳定,减少模块挤压变形和背景杂乱
- 图表数据正确性:柱状图柱高与数据一致、坐标轴刻度正确、百分比标注无误,箭头能准确指向对应数据点
- 学术论文页渲染:唯一支持arXiv风格学术论文页面生成的开源模型,单栏标题、双栏正文、脚注、页码、侧边水印均可精确排版
- 多场景覆盖:支持海报、流程图、对比表、明信片、菜谱、产品介绍、游戏卡牌、百科教程等100多种风格
- 连续性图文创作:业内首创单次调用即可输出图文交错的连贯内容,无需多模型串联
优缺点
优点:
- 8B参数规模达到开源信息图生成SOTA水平,IGenBench Q-ACC得分69.5,超过GPT-Image-1.5(55.0)和Qwen-Image-2.0(50.0)
- 小字渲染为开源模型中最强,RL专项奖励函数针对性解决了最棘手的高密度文字难题
- 版式与数据双稳定,减少信息图常见的数值幻觉与排版错乱
- 完全开源(Apache 2.0),支持商用,成本约为闭源方案的十分之一
- 消费级GPU可部署,GGUF量化后10-12GB显存即可运行
- 基于MoT架构解耦设计,信息图专项增强后视觉理解能力不退化(OneIG基准基本持平原版)
缺点:
- 总参数仅8B,通用推理能力与DeepSeek V4-Pro等旗舰模型仍有差距
- 输出价格8.1元/百万tokens,高于Qwen3.7-Max等部分竞品
- 官方基准数据尚未经独立第三方横向验证
- 长上下文(128K以上)场景速度明显衰减,从180-220 Tokens/s降至更低
- 与GPT-Image 2相比,视觉质感和逼真度稍逊,更偏概念化表达而非写实风格
如何使用
无需编写代码,可通过以下方式快速体验:
- 在线体验:访问商汤”办公小浣熊”(https://office.xiaohuanxiong.com/),点击【一图读懂】即可直接使用,无需配置
- API调用:注册商汤开放平台(https://platform.stepfun.com),获取API Key后调用,兼容OpenAI协议,可直接用现有OpenAI SDK接入
- 本地部署:从Hugging Face或ModelScope下载GGUF量化权重,在10-12GB显存的消费级GPU上即可运行;推荐参数组合:–cfg_scale 4.0、–timestep_shift 3.0、–num_steps 50
- Agent框架接入:在KiloCode、OpenClaw、Hermes Agent等框架中配置API端点,即可作为底层模型驱动信息图生成工作流
框架技术原理
模型基于商汤自研的NEO-unify原生统一架构,彻底摒弃了传统多模态模型必备的视觉编码器(VE)和变分自编码器(VAE),将像素与文字放入同一表征空间原生建模:
| 组件 | 设计 |
|---|---|
| 统一表征 | 输入端用两层卷积+GELU将图像转为token(每token对应32×32像素块),输出端用MLP直接预测原始像素块,消除模态转换损耗 |
| 原生MoT机制 | 底层共享自注意力上下文,但Q/K/V/O投影及MLP层根据token类型动态路由解耦——文本走自回归目标,视觉走像素流匹配目标,实现”知识共享、专才专用” |
| 三维RoPE | T/H/W三轴各有独立频率基,从底层对齐语言顺序与空间结构 |
| 分辨率自适应噪声尺度 | 噪声标准差按分辨率平方根比例动态调整,确保不同尺度下SNR分布一致 |
| 四阶段渐进训练+专项RL | 理解预热→生成预训练→统一中期训练→统一SFT,在MT阶段用高质量数据延长训练,RL阶段引入文字准确率与美学奖励函数 |
信息图增强版在此基础上,通过小字渲染RL奖励函数、版式稳定性数据集、图表数据一致性约束三条路径专项优化,同时MoT解耦设计保证视觉理解能力不退化。
创新点
- 开源模型首个信息图专项增强版本:不是通用生图模型的”顺便能画信息图”,而是从训练数据、奖励函数到评估指标全链路针对信息图场景重构
- NEO-unify实现端到端像素-文字建模:Hugging Face开发者社区评价”实现了纯粹的端到端像素-文字建模”,从根源解决压缩带来的细节丢失
- 专项增强不牺牲通用能力:MoT参数解耦设计让生成分支优化不干扰理解分支,OneIG基准与原版基本持平
- 8B规模打赢闭源商业模型:IGenBench Q-ACC 69.5分,超过GPT-Image-1.5(55.0)和Qwen-Image-2.0(50.0),是同级别唯一做到这一点的开源模型
- 业内首创连续性图文创作输出:单次单模型调用即可输出图文交错的连贯内容,图像间风格高度一致
评估标准
| 基准 | 得分 | 对比原版提升 | 行业对比 |
|---|---|---|---|
| BizGenEval Hard | 46.6 | +6.8(39.8→46.6) | 开源第一,Z-Image等未超10分 |
| BizGenEval Easy | 65.4 | +4.3(61.1→65.4) | 开源领先 |
| IGenBench Q-ACC | 69.5 | +18.2(51.3→69.5) | 超过GPT-Image-1.5(55.0)、Qwen-Image-2.0(50.0) |
| IGenBench I-ACC | 17.0 | +12.8(4.2→17.0) | 质的飞跃 |
| OneIG(英文) | 55.6 | +1.1(54.5→55.6) | 理解能力不退化 |
| OneIG(中文) | 53.3 | -0.5(53.8→53.3) | 理解能力不退化 |
评估维度覆盖布局、属性、文字、知识四个方面,信息图增强版在文字准确率和图表数据正确性上提升最为显著。
应用领域
- 营销与品牌传播:自动生成品牌海报、宣传长图,小字号法律声明与参数表格清晰可读,降低设计成本
- 学术研究与出版:生成arXiv风格论文页及数据对比表,解决公式错乱与脚注模糊问题
- 商业数据报告:制作财务图表与战略流程图,避免数值幻觉,为决策层提供准确可视化支撑
- 教育培训:生成课程知识图谱与教材插图,将抽象知识结构化呈现
- 生活服务:制作电子菜单、旅行明信片、菜谱步骤图,中文小字信息准确,满足印刷与线上传播需求
项目地址
| 资源 | 链接 |
|---|---|
| Hugging Face | https://huggingface.co/sensenova/SenseNova-U1-8B-MoT-Infographic |
| GitHub | https://github.com/OpenSenseNova/SenseNova-U1 |
| ModelScope(国内) | https://modelscope.cn/models/SenseNova/SenseNova-U1-8B-MoT-Infographic |
| GGUF量化版本 | Hugging Face社区已自发提供 |
| GitCode | https://ai.gitcode.com/SenseNova/SenseNova-U1-8B-MoT-Infographic |
| 在线体验(办公小浣熊) | https://office.xiaohuanxiong.com/ |
| 技术报告 | https://arxiv.org/abs/2605.12500 |
| 开源协议 | Apache 2.0 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...
AI全网资源导航每日收集国内外热点AI/人工智能/工具/模型/框架以及最新的AI学习资料/课程等,在这个全新的AI时代,助力每一个人,赋能每一个具体业务场景,与所有人一起努力向前!
