Polar : 英伟达开源的智能体强化学习训练框架
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
主要介绍
2026年5月28日,英伟达研究团队正式开源了名为 Polar 的强化学习训练框架,专门为代码智能体(Agent)量身打造。它的核心使命只有一个:让 Codex、Claude Code、Qwen Code 等现有主流代码智能体,在不修改任何一行原生代码的前提下,无缝接入 GRPO(广义相对策略优化)强化学习训练。
随着代码智能体从简单的单步任务迈向仓库级修改、操作系统交互等复杂长流程任务,开发者越来越依赖成熟的执行框架(Harness)。然而传统强化学习接入方式要求将这些框架强行改写为 env.init()、env.step() 等标准接口,不仅成本极高,还会丢失工具调用链路、多轮对话上下文等关键训练信号。Polar 正是为解决这一行业痛点而生,开源仅一周 GitHub star 即突破 5000,超过 100 个代码智能体项目宣布集成,堪称代码智能体训练领域的一座里程碑。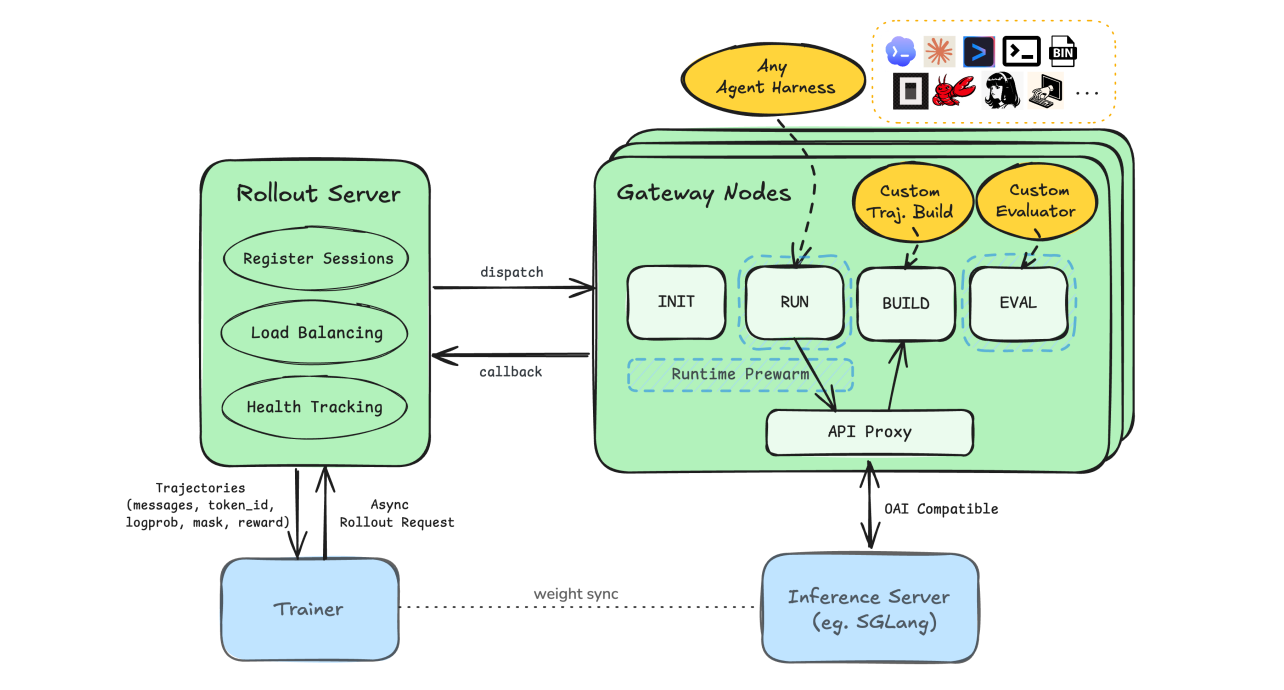
功能特点
| 特性 | 说明 |
|---|---|
| 零侵入接入 | 无需修改 Codex CLI、Claude Code 等智能体运行外壳的任何代码 |
| 全 API 兼容 | 支持 Anthropic、OpenAI、Google 三大主流 API 风格,透明代理无感拦截转发 |
| 轨迹自动构建 | 实时记录提示词、采样 Token、对数概率,自动重组为 GRPO 训练所需的 trajectory 数据 |
| 双组件架构 | Rollout Server 负责调度与持久化,Gateway Node 管理会话全生命周期 |
| prefix_merging 优化 | 训练更新次数从 1185 次降至 218 次,墙钟时间缩短约 5.39 倍 |
| READY 缓冲机制 | 运行时预热与评测预热并行执行,消除长尾任务对 GPU 的阻塞 |
优缺点
优点:
- 接入成本极低——不改写执行框架,保留全部原生功能细节,真正的”即插即用”
- 训练效率飞跃——GPU 利用率从 20.4% 飙升至 87.7%,算力浪费大幅减少
- 性能提升惊人——Codex 框架 pass@1 从 3.8% 跃升至 26.4%,涨幅高达 594.74%
- 生态兼容性强——开源一周即获 5000+ star,覆盖金融、自动驾驶等多领域
缺点:
- 依赖 GRPO 训练体系,对硬件有一定门槛,并非所有任务都能获得同等收益
- 适用范围受限于代码智能体类型,通用性尚待验证
- GRPO 训练的稳定性和收敛速度因任务复杂度而异,复杂场景下可能需要额外调优
- 相比同日发布的竞品(如谷歌 DeepMind 的 AlphaCode Train v2),Polar 虽兼容性更强,但后者在自家生态内可能有更深的优化
如何使用
使用 Polar 无需编写任何代码,整体流程可分为四步:
- 部署双组件——启动 Rollout Server(负责任务调度与状态持久化)和 Gateway Node(负责会话生命周期管理)
- 配置透明代理——在现有代码执行框架与模型推理服务器之间插入 Polar Gateway,它会自动拦截并转发所有 API 请求
- 接入 GRPO 训练——将 Polar 输出的轨迹数据喂给 GRPO 训练器,模型即可在真实工具调用流程中持续优化
- 启用 prefix_merging——开启该优化策略后,训练效率自动提升约 5.4 倍,GPU 资源得到充分利用
整个过程对开发者透明,现有智能体框架无需任何改动。
框架技术原理
Polar 的技术核心在于 “以 API 边界为训练入口”,而非改造执行框架本身。
架构层面: 系统由两大组件构成——
- Rollout Server:负责任务提交、会话调度、状态持久化和回调接收
- Gateway Node:管理会话执行全生命周期,包括运行时启动、框架准备、轨迹构建、结果评测和资源回收
数据流层面: Gateway 在转发 API 请求时,实时捕获 prompt、采样 token、对数概率(log probs)和响应内容,将这些碎片信息重组为强化学习训练器可直接消费的完整轨迹(trajectory)。
效率优化层面: 通过将初始化、运行中、后处理流程拆分到独立工作池,配合 READY 缓冲区实现预热并行,prefix_merging 技术将重复请求合并处理,最终实现更新次数减少 82%、训练耗时压缩至原来的 18%。
创新点
- 非侵入式训练边界——不改执行框架,只在模型 API 边界处”插针”采集数据,这是对传统强化学习接入范式的根本性颠覆
- 黑盒化兼容设计——无论底层是 Anthropic、OpenAI 还是 Google 的 API,Polar 都能无感适配,真正做到”任何 Harness 都能训”
- 异步并行架构——READY 缓冲池 + 独立工作池的设计,让 GPU 不再被长尾任务空等,利用率从 20.4% 拉升至 87.7%
- 轨迹动态重构——不依赖框架原生输出,而是在请求流转中实时构建训练轨迹,保证了数据完整性
评估标准
Polar 的性能以 SWE-Bench Verified 基准测试为核心衡量指标,基于同一 Qwen3.5-4B 底座模型,在四种代码执行框架上的 pass@1 表现如下:
| 框架 | 训练前 | 训练后 | 提升幅度 |
|---|---|---|---|
| Codex | 3.8% | 26.4% | +594.74% |
| Claude Code | 29.8% | 34.6% | +16.1% |
| Qwen Code | 34.6% | 35.2% | +1.6% |
| Pi | 34.2% | 40.4% | +18.1% |
效率指标:
- 墙钟时间:189.5 分钟 → 35.2 分钟(5.39 倍加速)
- GPU 利用率:20.4% → 87.7%
- 更新次数:1185 次 → 218 次(减少 82%)
应用领域
- AI 驱动的软件开发自动化——代码仓库维护、Bug 修复、功能开发
- 金融领域智能体——自动化交易策略生成与回测
- 自动驾驶——决策智能体的强化学习训练
- 自动化运维与软件测试——长流程任务的智能体优化
- 浏览器自动化操作——多步网页交互任务的持续改进
未来还有望扩展至更多需要多步决策的复杂智能体场景。
项目地址
- 论文:https://arxiv.org/pdf/2605.24220
- GitHub:https://github.com/NVIDIA/Polar(开源一周 star 破 5000,100+ 项目已集成)
Polar 的出现,标志着 AI 智能体训练正从实验室的手动调参,加速迈向可规模化复制、高可靠交付的工业化生产新纪元。
相关文章
