8月15日·Nature:出版商天价出售论文数据,AI训练背后的版权与利益争议
8月15日·周四 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
Nature:出版商天价出售论文数据,AI训练背后的版权与利益争议
Nature杂志的一篇文章揭露了学术出版界的一个惊人内幕:科研论文正被用作训练人工智能模型的数据,而这一过程往往在论文作者不知情的情况下进行。一些出版商通过出售论文数据给科技公司,已经赚取了巨额利润,如Wiley出版商就通过这种方式赚取了2300万美元,而辛苦撰写论文的作者们却得不到任何收入。这种现象引发了版权和道德的争议。学术数据集如S2ORC和Pile,因包含大量学术文本,已成为训练大型语言模型(LLM)的重要资源。与此同时,大型科技公司也在积极购买高质量数据集,以提升其AI模型的性能。然而,证明论文被用于LLM训练非常困难,且版权争议复杂,因为LLM并未直接复制内容,而是通过学习生成新文本。目前,一些研究者正在尝试通过技术手段检测论文是否被用作训练数据,但这一领域的法律和道德规范仍待明确。来源:微信公众号【新智元】

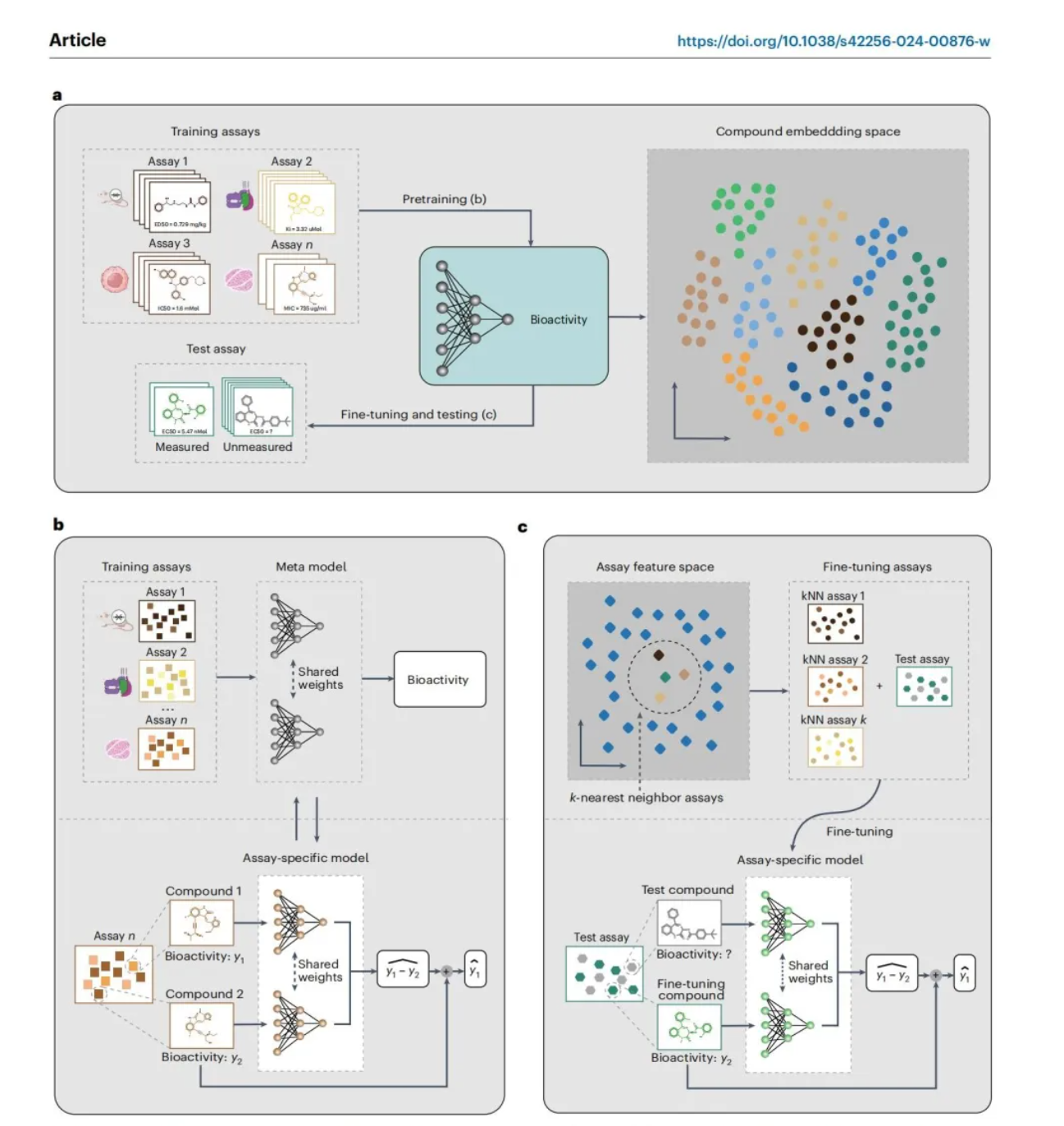
北大张铭教授团队ActFound模型:突破生物活性预测,助力癌症药物研发
北京大学计算机学院张铭教授团队与华盛顿大学等联合团队在国际AI顶刊Nature Machine Intelligence上发表了他们的最新研究成果——生物活性基础模型ActFound。该模型利用ChEMBL数据库中160万个实验测量的生物活性数据进行训练,成功解决了现有生物活性预测方法中的局限性,显著提升了跨域生物活性预测、先导小分子优化以及癌症药物反应预测的准确性和效率。ActFound模型采用成对学习方法和元学习技术,有效避开了不同实验间生物活性不兼容的问题,并在少量数据情况下增强了预测准确度。在多个生物活性评测基准数据集上,ActFound展现了出色的预测能力和泛化能力,其性能甚至可与基于物理的计算工具FEP+相媲美,但计算效率更高。这项工作不仅为药物研发领域带来了创新工具,也为AI在生物医药应用中的发展提供了新方向。来源:微信公众号【新智元】
ACL 2024奖项公布:华科大破译甲骨文最佳论文之一、GloVe时间检验奖
在泰国曼谷举行的第62届ACL(Association for Computational Linguistics)大会上,华中科技大学的研究成果《Deciphering Oracle Bone Language with Diffusion Models》荣获最佳论文奖之一。该研究利用扩散模型技术,为破译约3000年前中国商朝的甲骨文提供了新方法,开辟了古代语言AI辅助分析的新方向。此外,斯坦福大学、加州大学尔湾分校、得克萨斯大学奥斯汀分校合作的论文《Mission: Impossible Language Models》同样获得最佳论文奖,该研究挑战了关于大型语言模型学习能力的现有理论。本届大会还颁发了时间检验奖、终身成就奖以及多项其他奖项,以表彰对自然语言处理和计算语言学领域产生深远影响的研究成果。来源:微信公众号【机器之心】

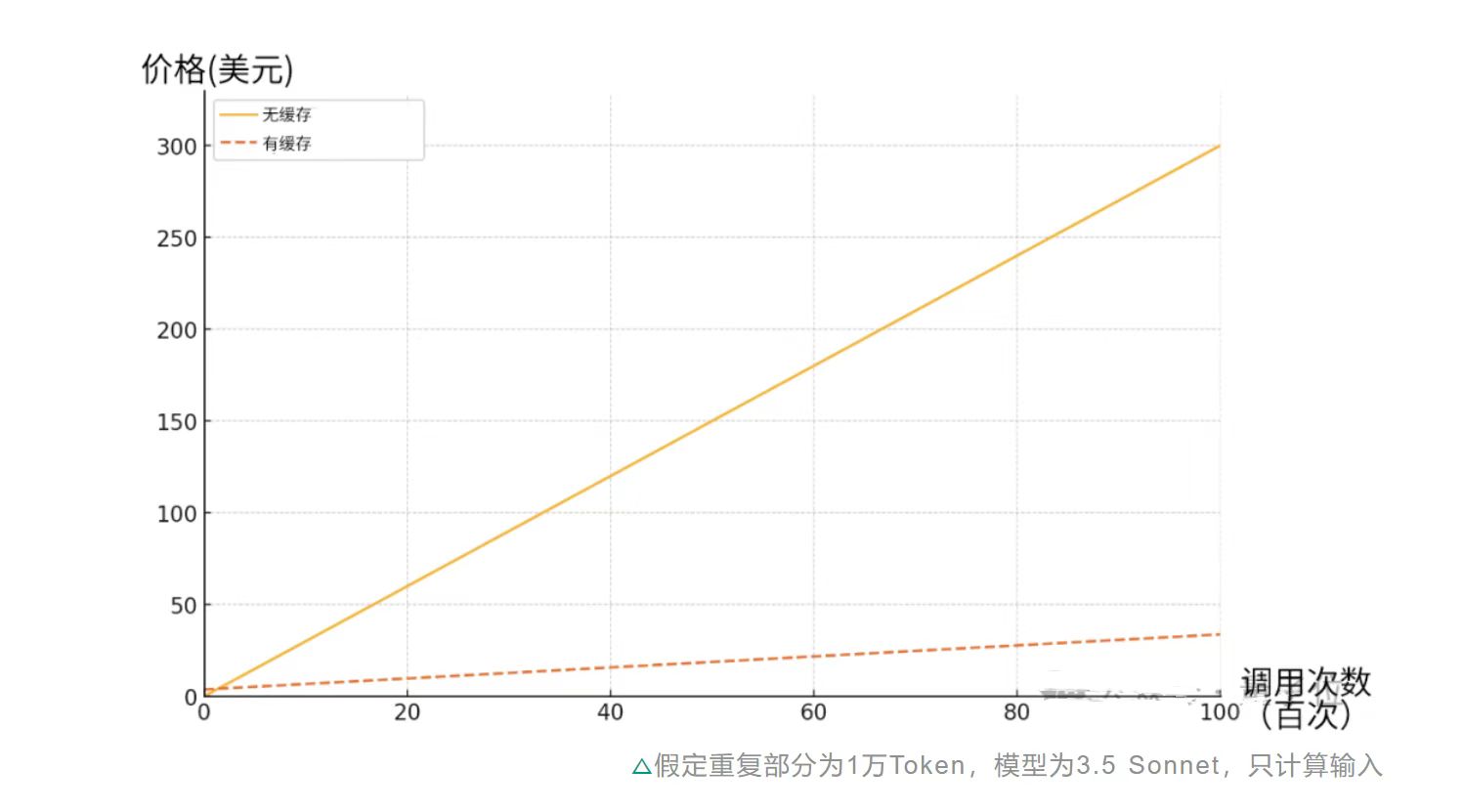
Claude推出API长文本缓存功能:成本直降90%,效率大幅提升
Claude最近推出了一项新功能——API长文本缓存,这一更新显著提升了处理长文本的效率,并大幅降低了成本,最高可节省90%。这项功能允许API记住一整本书或整个代码库等内容,避免了重复输入的需要。谷歌的Gemini和国内的Kimi以及DeepSeek团队都已相继推出了类似功能。提示词缓存功能不仅减少了延时,还允许用户通过发送大量prompt对模型进行更有效的”微调”。Claude的这一新功能特别适合代码和长文档处理,例如降低扩展会话的成本和延迟、改善代码自动补全和问答功能、在提示中纳入完整的长格式材料等。价格方面,提示词缓存的价格分为写入和读取两部分,随着缓存被反复读取的次数增加,节约的成本也越多。这项功能目前已支持3 Haiku和3.5 Sonnet模型,Opus模型也将在后续更新中支持。开发者们认为这项更新对于降低成本和提升效率具有重大意义。来源:微信公众号【量子位】
清华唐杰团队突破:大模型实现2万字长文本生成
清华大学智谱AI团队的最新研究在大模型文本生成长度上取得了显著突破。该团队成功扩展了GLM-4和Llama-3.1等模型的输出能力,将相同问题下的输出结果从1800字增加到7800字,实现了超过四倍的增长。这一进展对于提升内容创作的全面性和模型的创造性具有重要意义。研究由智谱AI创始人、清华大学教授李涓子和唐杰共同领衔,相关论文和代码已在GitHub上开源。
研究的核心包括分析现有文本生成长度的限制因素,提出AgentWrite方法,以及扩展大型语言模型(LLM)的输出窗口大小。通过构建测试工具LongWrite-Ruler,研究人员发现,所有测试的大模型在生成超过2000字的文本时都遇到了困难。进一步分析表明,现有模型在输出长度上受限主要是因为监督式微调(SFT)数据集中缺少长输出样本。为了克服这一限制,研究人员提出了AgentWrite,这是一个基于Agent的pipeline,允许将超长文本生成任务分解为多个子任务,每个子任务处理其中的一段。
利用GPT-4o生成的6000个长输出SFT数据构成了数据集LongWriter-6k,这些数据被添加到训练过程中,显著提升了模型的输出长度。评估结果显示,使用AgentWrite后模型输出长度明显增加,其中GLM-4-9B通过直接偏好优化(DPO)实现了最佳性能。网友们已经抢先体验了这项技术,并在Reddit上分享了生成《罗马帝国衰落史》的成果。研究团队表示,未来将进一步扩展模型的输出长度和质量,同时研究如何在不牺牲生成质量的情况下提高效率。来源:微信公众号【量子位】

【今日案例】
中国AI盛典与AI版百家争鸣
https://yuanbao.tencent.com/bot/app/share/chat/10b52710fe6db125124d744ca53aaaa1
相关文章
