8月16日·知网起诉秘塔AI搜索侵权:搜到论文摘要就算侵权?
8月16日·周五 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
知网起诉秘塔AI搜索侵权:搜到论文摘要就算侵权?
中国知网对创业团队秘塔AI搜索提起侵权诉讼,声称秘塔AI搜索未经许可,通过搜索功能提供知网学术文献的题录及摘要,构成严重侵权行为。知网要求秘塔立即断开搜索结果到知网网站的链接,并表示如果需要商务合作可与知网联系。秘塔AI搜索在其公众号上发表了声明,认为文献摘要和题录应具有独立性,能够使读者快速获取必要信息,且知识的价值在于流动。秘塔AI搜索的学术版块仅收录了论文摘要和题录,并未收录文章内容本身,阅读全文需要通过来源链接跳转至知网网站。
秘塔AI搜索表示,将不再收录知网文献的题录及摘要数据,转而收录其他中英文权威知识库的文献题录及摘要数据,并欢迎其他数据库来合作探讨。此外,秘塔AI搜索的界面没有变化,只是在顶部多了一个“侵权告知”的消息链接。秘塔AI搜索的学术搜索功能允许用户通过输入关键词获取全网总结的结果,包括技术的解读、相关事件、人物及消息来源等。然而,知网此次诉讼针对的是秘塔AI搜索在学术栏目中展示的论文题目和摘要的浮窗页面。
对于知网的这一行为,许多网友表示不理解,认为AI搜索只是提供了一个入口。其他国内外的AI搜索产品,如昆仑万维的天工AI搜索、360 AI搜索以及国外的Perplexity,似乎并没有直接链接到某篇具体的论文,而秘塔AI搜索的展示结果则是一种特色。此事件让人联想到知网过去因侵权问题被罚款和整改的情况,现在又引发了争议。
来源:微信公众号【量子位】
Tavus推出超低延迟对话视频AI:几乎无感知的等待,红杉和YC投资
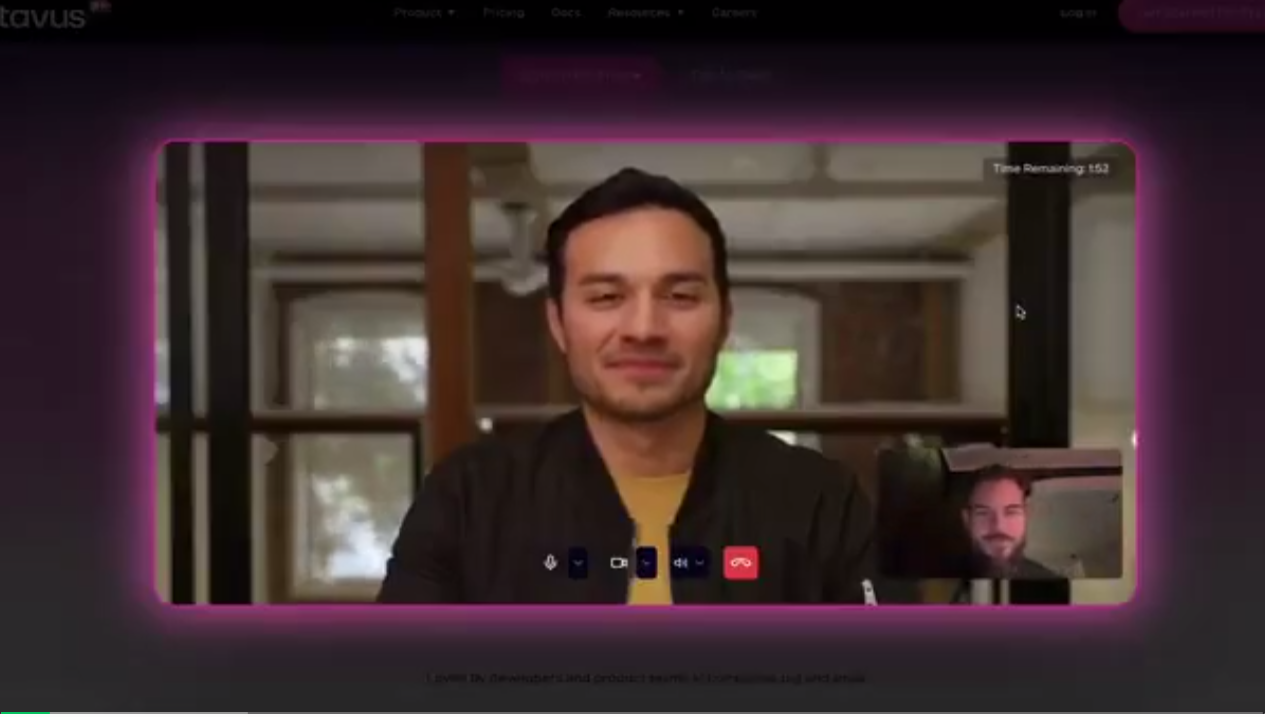
一家名为Tavus的创业团队开发了一款具有超低延迟的对话视频AI产品,它能够提供接近实时的交流体验,延迟小于一秒。这款产品名为Conversational Replicas by Tavus,主要功能是创建一个沉浸式的AI生成视频体验。上线后迅速登上Producthunt新品热榜第一,受到了用户的热烈欢迎。
Tavus的AI产品特点包括:
- 极低的延迟,小于一秒
- 现实且智能的数字孪生形象
- 即插即用的端到端构建块
- 模块化、可定制的组件,例如LLM语音合成
用户可以在网页端试玩这款AI产品,体验与虚拟形象“卡特”的对话。卡特是Tavus塑造的一名员工,以幽默和乐于助人的方式回应用户。Tavus的AI能够快速响应用户发言,尽管目前还不支持中文对话,但其AI确实能够“用眼睛看”,并且口型与说话内容几乎完全同步。
Tavus背后的技术是Phoenix-2模型,这是一个结合了音频和文本驱动的3D模型和2D GANs的模型,能够生成逼真的短视频。Phoenix-2模型利用3D高斯泼溅技术,提高了渲染效率和视频质量。
Tavus团队由来自Amazon、Descript、Google和Apple等公司的成员组成,已经获得了红杉、Scale VC、YC的A轮投资,融资额约1800万美元。团队追求1秒或更短的延迟,以模拟人类间的自然对话。
来源:微信公众号【量子位】
FancyTech:以垂直模型引领AIGC商业化落地的技术路径
FancyTech,一家中国创业公司,在AIGC(人工智能生成内容)技术商业化领域取得了显著成就。该公司专注于开发面向商业视觉内容生成的垂直模型,通过标准化产品快速拓展市场,证明了垂直模型在产业落地方面的优势。
FancyTech的核心优势在于其自研的视频垂直模型DeepVideo,该模型通过精细的数据采集和训练方法,实现了商品的高度还原和自然融合。公司通过积累大量的3D训练数据,并引入空间智能的概念,指导2D内容生成,使模型更好地理解3D物理世界,从而提升2D视觉内容的生成效果。
FancyTech的技术探索包括多模态特征器的提出,以及对视频生成底层链路的重建。这些创新使得生成的视频内容不仅商品还原度高,而且能够控制商品在视频中的运动,避免形变,实现与背景的超融合。
此外,FancyTech还注重数据收集的光照和阴影效果,通过模拟真实拍摄场景的灯光设置,收集自然光影数据,进一步提升内容的真实感。
FancyTech的垂直模型不仅在技术上取得了突破,而且在商业化应用上也取得了显著成效。公司与多个国际品牌和电商平台建立了合作关系,并在欧洲获得了LVMH创新大奖。
AIGC技术的发展为个人和品牌提供了前所未有的创作和生产力提升机会。FancyTech的垂直模型让普通用户和企业能够轻松跨越专业门槛,将创意快速转化为现实,享受AIGC技术带来的时代红利。
来源:微信公众号【机器之心】

英伟达优化Llama 3.1模型:剪枝和蒸馏技术大幅减少参数量,性能不减
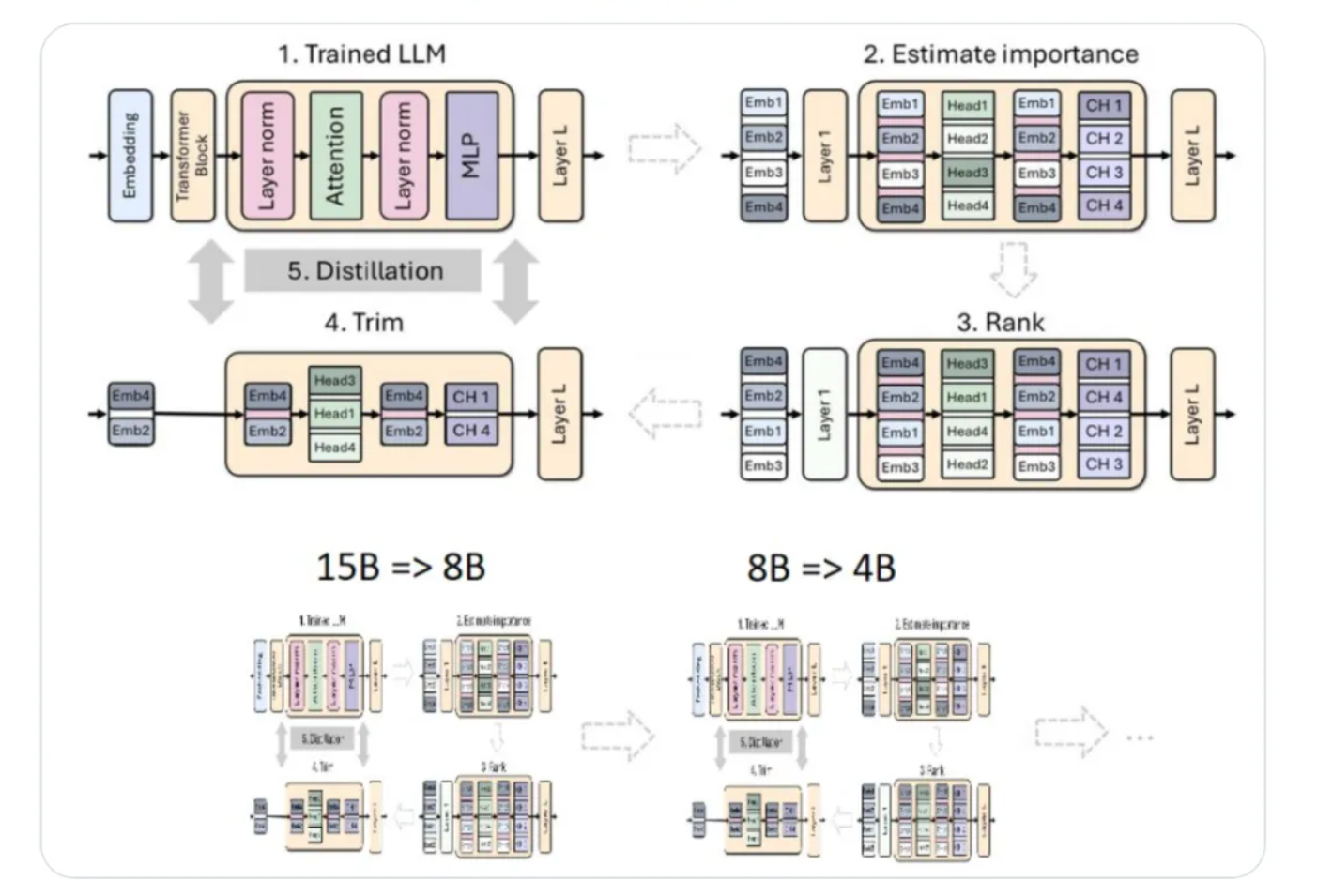
英伟达最近的研究展示了如何通过结构化权重剪枝和知识蒸馏技术,将Llama 3.1系列中的8B参数模型优化为更小型的4B参数模型,同时保持了优越的性能。这项工作不仅得到了图灵奖得主、Meta首席AI科学家Yann LeCun的认可,而且证明了小型语言模型(SLM)在资源受限的情况下也能有出色的表现。
Llama-3.1-Minitron 4B模型在多个基准测试中与其他类似大小的顶尖开源模型相比,展现出了更好的性能。英伟达的研究团队从15B模型开始,通过评估组件重要性、剪枝、再训练,最终实现了模型的精简。他们采用了基于激活的纯重要性评估策略,这种方法简单且具有成本效益。
在剪枝策略上,英伟达发现宽度剪枝(隐藏维和MLP中间维的剪枝)比深度剪枝更有效,尤其是在参数规模较小的模型上。此外,研究团队还发现仅使用蒸馏损失进行再训练比常规训练更有效。
Llama-3.1-Minitron 4B模型经过NVIDIA TensorRT-LLM优化后,在不同用例下显示出了高吞吐量,其性能是原始Llama 3.1 8B模型的2.7倍至1.8倍。此外,FP8精度部署相比FP16可以进一步提升性能约1.3倍。
这项研究表明,通过剪枝和知识蒸馏,可以高效地获得更小尺寸的语言模型,这些模型在保持高准确性的同时,减少了计算资源的需求。英伟达的这项工作为AI模型的优化和部署提供了新的思路。
来源:微信公众号【机器之心】
DeepMind科学家分享AI提效实例:LLM助力工作效率翻倍
DeepMind研究科学家Nicholas Carlini近期发表文章,分享了他如何利用大型语言模型(LLM)在日常工作中提升效率。Carlini通过长达8万字的文章列举了50个使用AI的实例,这些实例仅占他所有AI应用的不到2%。他认为LLM并没有被过度炒作,尽管存在AI泡沫,但AI的进展远不止于此。
在过去一年中,Carlini通过与大语言模型的交互,显著提高了自己在研究项目和副业项目中编写代码的速度,至少提升了50%。他使用LLM的实例包括构建网络应用程序、学习新框架、自动转换程序语言以提高性能、简化大型代码库、编写研究论文的初始代码、自动化单调任务等。
Carlini将这些应用分为”帮助我学习”和”自动化无聊任务”两大类。他强调,尽管这些应用可能并不花哨,但它们都是完成实际工作所需的,LLM的魅力在于自动化完成工作中那些乏味的部分。
作为一个安全研究员,Carlini非常清楚人工智能模型的局限性,但他依然宣称”大语言模型为我的工作效率创造了自互联网诞生以来的最大提升”。他通过实际使用LLM的例子,反驳了”LLM只是炒作”的观点,并相信其他人也能从中受益。
来源:微信公众号【新智元】
【今日案例】
2024年知名人士对生成式人工智能在教育领域应用的观点
https://yuanbao.tencent.com/bot/app/share/chat/eec7ce23989191919ec6a0363b9f4c27
相关文章
