11月08日·无人车大战打响!美国萝卜日爆8000单破纪录,中美对决已到关键转折点
11月08日·周五 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的o g zAI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
无人车大战打响!美国萝卜日爆8000单破纪录,中美对决已到关键转折点
美国自动驾驶汽车Waymo在旧金山日均服务单量超8800单,超越出租车,标志着自动驾驶技术已开始变革传统出行方式。与此同时,中国无人驾驶市场巨大,百度旗下的萝卜快跑正成为通勤首选,日均服务超1万单。在全球人工智能竞争中,中美两国在自动驾驶领域进入决胜时刻。随着技术进步和政策支持,自动驾驶不仅重塑未来生产力,还将推动就业结构的深刻变革。来源:微信公众号【新智元】

类Sora模型能否理解物理规律?字节豆包大模型团队系统性研究揭秘
字节跳动豆包大模型团队的最新研究显示,尽管视频生成模型能够根据文本提示生成逼真视频,但它们并未真正理解物理规律。该团队通过合成物理场景视频训练主流DiT架构的视频生成模型,并测试其生成的视频是否符合力学定律。研究发现,即使扩大模型参数和训练数据量,模型依然无法抽象出一般物理规则,如牛顿第一定律和抛物线运动。这一发现得到了图灵奖得主Yann LeCun的认可,他强调基于概率的大语言模型无法理解常识,包括物理规律。这项研究为视频生成模型的物理规律理解能力划上了不等号,指出模型更像是“抄作业”的学生,无法做到举一反三。来源:微信公众号【机器之心】
FreeVS:全生成式车辆行驶轨迹视频合成器
中国科学院自动化所团队提出了一种名为FreeVS的全生成式新视角合成方法,该方法能够无需场景重建,直接在真实场景中渲染任意车辆行驶轨迹的视频。与传统基于场景重建的方法相比,FreeVS能够显著减少耗时,避免了在缺少观测的新视角上图像渲染不合理的问题。该技术通过从稀疏点云投影中恢复相机成像,类似于Inpainting模型,基于稀疏但可靠的点云投影点补全目标图像。FreeVS在测试阶段能够将图像信息染色的场景三维点云投影至任意所需视角,控制图像生成结果,同时支持车辆行驶模拟与场景编辑,展现出在新车辆运动轨迹下合成视频的潜力。来源:微信公众号【机器之心】

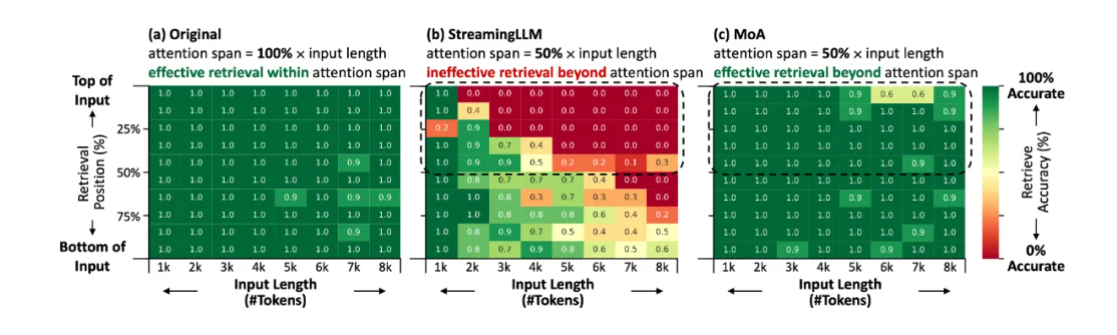
MoA混合稀疏注意力方案:提升长文本生成效率
清华大学、无问芯穹和上海交通大学的研究团队提出了一种名为MoA(Mixture of Sparse Attention)的混合稀疏注意力方案,旨在加速长文本生成并显著提升吞吐率。MoA通过为不同的注意力头和层定制独特的稀疏注意力配置,使得在保持平均注意力跨度不变的情况下,有效上下文长度提升约3.9倍。实验显示,MoA在Vicuna-7B、Vicuna-13B和Llama3-8B模型上,将长文本信息检索准确率提高了1.5-7.1倍,同时在运行效率上,相比于现有方法,MoA将7B和13B稠密模型的生成吞吐量提升了6.6-8.2倍。这项工作为大语言模型的压缩和效率优化提供了新的思路。来源:微信公众号【机器之心】
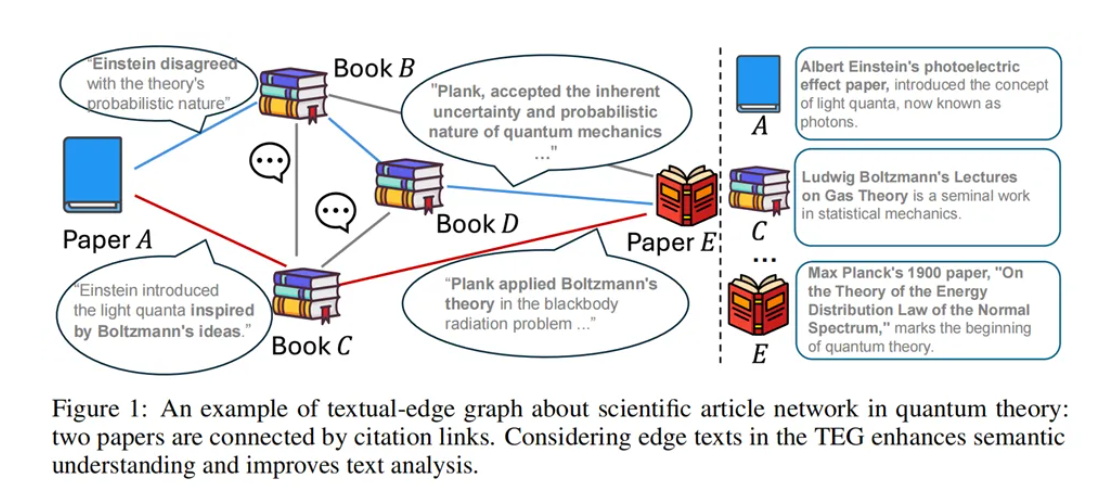
TEG-DB:首个大规模文本边图基准数据集发布
由上海大学、山东大学、埃默里大学等学术机构联合推出的TEG-DB,作为首个大规模文本边图(Textual-Edge Graphs, TEGs)数据集和基准测试,已被NeurIPS 2024接收。TEG-DB包含4个领域9个统一格式的TEG数据集,覆盖从小型到大型不同规模,提供丰富的节点和边原始文本数据。该基准测试旨在解决TEGs领域在数据集、格式统一性及模型比较分析上的挑战,推动图数据挖掘技术发展。研究人员还开发了TEGs研究的标准化流程,并进行了广泛的基准实验,深入分析了不同模型及预训练语言模型(PLMs)在TEGs上的效果。TEG-DB的发布为自然语言处理和图神经网络社区提供了宝贵的资源,促进了对文本边图的合作研究。来源:微信公众号【新智元】
【今日案例】
马斯克大力支持特朗普竞选总统的目的是什么?
相关文章
