7月12日·英伟达携手FlashAttention-3,GPU性能大幅提升
7月12日·周五 AI工具和资源推荐
AI智库导航-aiguide.cc为您提供最新的AI新闻资讯和最新的AI工具推荐,在这里你可以获得用于营销的AI聊天机器人、AI在商业管理中的应用、用于数据分析的AI工具、机器学习模型、面向企业的AI解决方案、AI在商业客户服务中的应用、AI和自动化工具等。
英伟达携手FlashAttention-3,GPU性能大幅提升
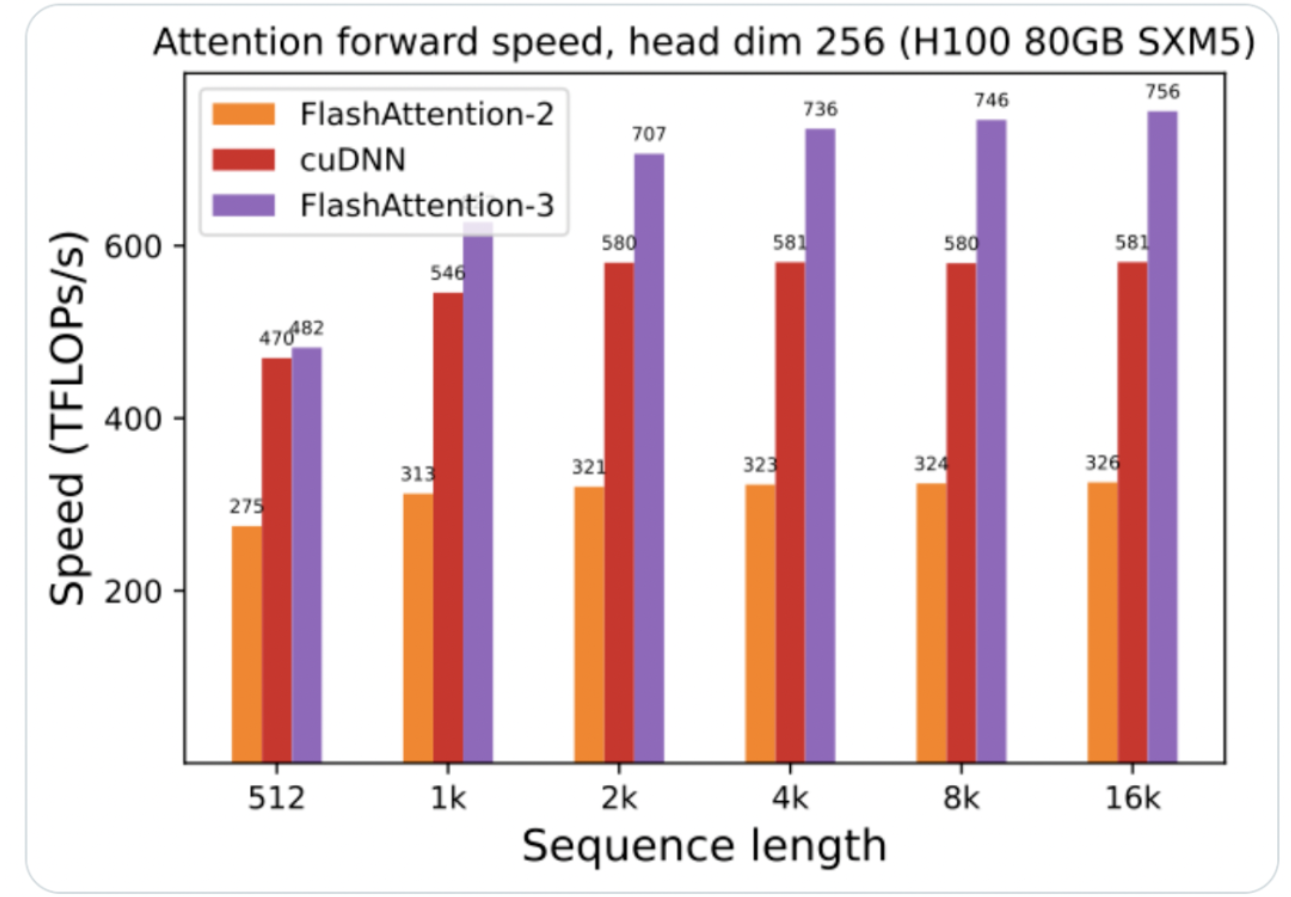
英伟达与FlashAttention-3的合作实现了GPU性能的显著提升。FlashAttention-3是专为Hopper架构优化的第三代注意力机制,其训练速度提升1.5-2倍,FP16下计算吞吐量高达740TFLOPs/s,达到理论最大吞吐量的75%。此外,FlashAttention-3在FP8下速度接近1.2PFLOPs/s,误差比标准Attention减少2.6倍。这项技术通过异步加载、乒乓调度和分块量化等创新手段,大幅提升了GPU的计算效率和精度,为大模型训练和推理带来革命性的进步。来源:微信公众号【量子位】
昆仑万维发布全能AI智能体Cradle,开启通用计算机控制新篇章
昆仑万维联合多家顶尖机构发布了Cradle,这是首个能够无需训练即可直接控制键盘鼠标的通用AI智能体框架。Cradle不依赖任何内部API,能够与任意开闭源软件进行交互,无论是游戏还是日常办公软件,如美图秀秀、剪映和飞书等,都能轻松驾驭。Cradle由六大模块构成,通过自我反思、任务推断和行动规划等环节,实现对计算机的全面控制。这一创新框架的开源,标志着通用计算机控制智能体(GCC Agents)研究向前迈出了重要一步,为实现更广泛的人工智能应用铺平了道路。来源:微信公众号【新智元】
Andrej Karpathy实现低成本高效训练GPT-2模型
前特斯拉Autopilot负责人、OpenAI科学家Andrej Karpathy在其项目”llm.c”中展示了如何仅用672美元和24小时在一个8XH100 GPU节点上训练出具有15亿参数的GPT-2模型。这一成果得益于硬件、软件和数据集的显著进步,使得训练成本大幅下降。Karpathy分享了他的训练心得,指出使用C/CUDA实现的”llm.c”项目简化了训练流程,无需依赖复杂的Python环境,直接利用CUDA工具进行高效训练。他还预告了项目未来的新方向,包括对fp8的支持、推理、微调和多模态能力等,旨在提供一个简单、干净的训练堆栈,推动大语言模型的发展。来源:微信公众号【机器之心】
商汤科技加入中国移动人工智能大模型评测联盟
在2024年WAIC期间,中国移动成立了人工智能大模型评测联盟(弈衡),商汤科技作为创始成员之一受邀加入。该联盟的成立旨在推动中国人工智能技术的发展,提升国产AI产品的质量和竞争力。联盟将致力于构建大模型评测标准,促进资源共享,并推动AI产业链的成熟应用。商汤科技凭借其AI大装置SenseCore,推出了性能提升30%的「日日新SenseNova 5.5」大模型,该模型在多项核心指标上实现对标GPT-4o,为用户带来了全新的AI交互体验。来源:搜狐新闻

燧原科技张亚林谈国产AI算力商业化与生态构建
燧原科技创始人兼COO张亚林在逆全球化背景下,就国产AI算力的商业落地和生态构建进行了深入探讨。张亚林认为,AI算力是推动中国AI技术发展的关键,而算力中心的商业化落地需要AIDC与AIGC形成”双轮驱动”。他强调,构建完整的算力中心生态圈是实现可持续发展的重点,通过开源节流和持续构建生态护城河来应对市场环境的挑战。张亚林还展望了中国在AI领域的垂直应用优势,以及云边端协同发展的未来趋势。来源:钛媒体
【今日案例】
秘塔分析:Character.ai产品和商业模式
相关文章
